

¡Hola a todos! En este post, exploraremos cómo combinar de manera eficiente los datos de múltiples...
Apache Hop es una herramienta poderosa y flexible para crear proyectos de datos, pero ciertos diseños pueden enfrentarse a bloqueos (también conocidos como "deadlocks", bloqueos de procesos, estancamientos o cuelgues).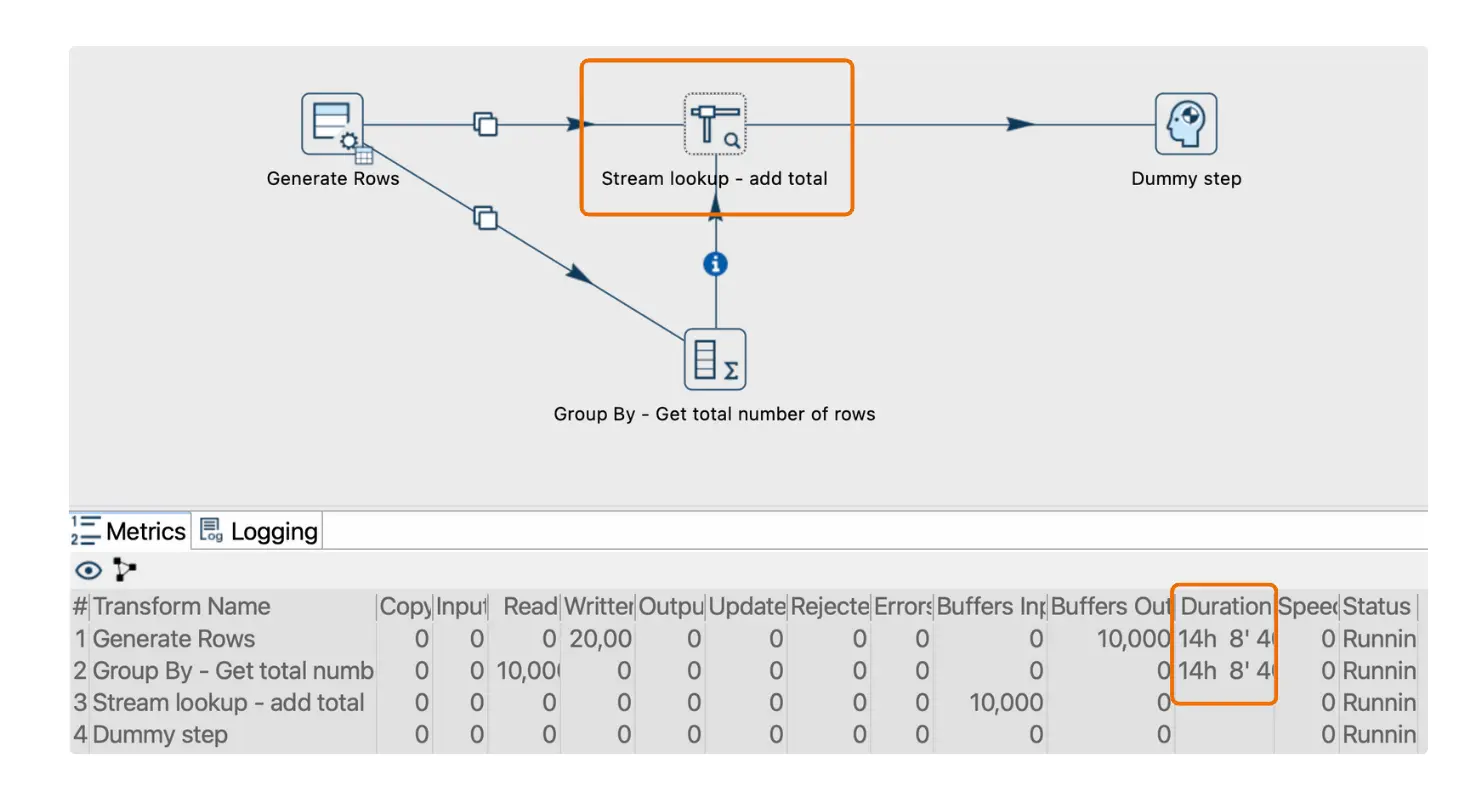
Los bloqueos ocurren cuando diferentes transformaciones dentro de un pipeline se impiden mutuamente finalizar, lo que hace que todo el pipeline se detenga indefinidamente. Este artículo se centra en una causa común de bloqueo al usar la transformación "Stream lookup" y ofrece soluciones prácticas para evitarlo.

Entendiendo los bloqueos en pipelines
Los bloqueos en Apache Hop pueden ocurrir por varias razones:
- Bloqueos externos: Cuando la propia base de datos coloca bloqueos en una tabla, puede impedir el progreso del pipeline.
- Problemas de diseño del pipeline: Transformaciones configuradas para bloquearse hasta que se completen transformaciones anteriores pueden generar bloqueos, especialmente al trabajar con grandes conjuntos de datos.
- Límites de búfer y tamaño de fila (rowset): En pipelines donde los flujos se dividen y luego se vuelven a unir, establecer un tamaño de fila adecuado es crucial para evitar bloqueos.
Cómo "Stream lookup" puede causar bloqueos
Una de las situaciones más comunes de bloqueo surge al usar la transformación "Stream lookup", especialmente si el pipeline procesa una gran cantidad de filas. A continuación, se explica cómo sucede y cómo prevenirlo.
Escenario
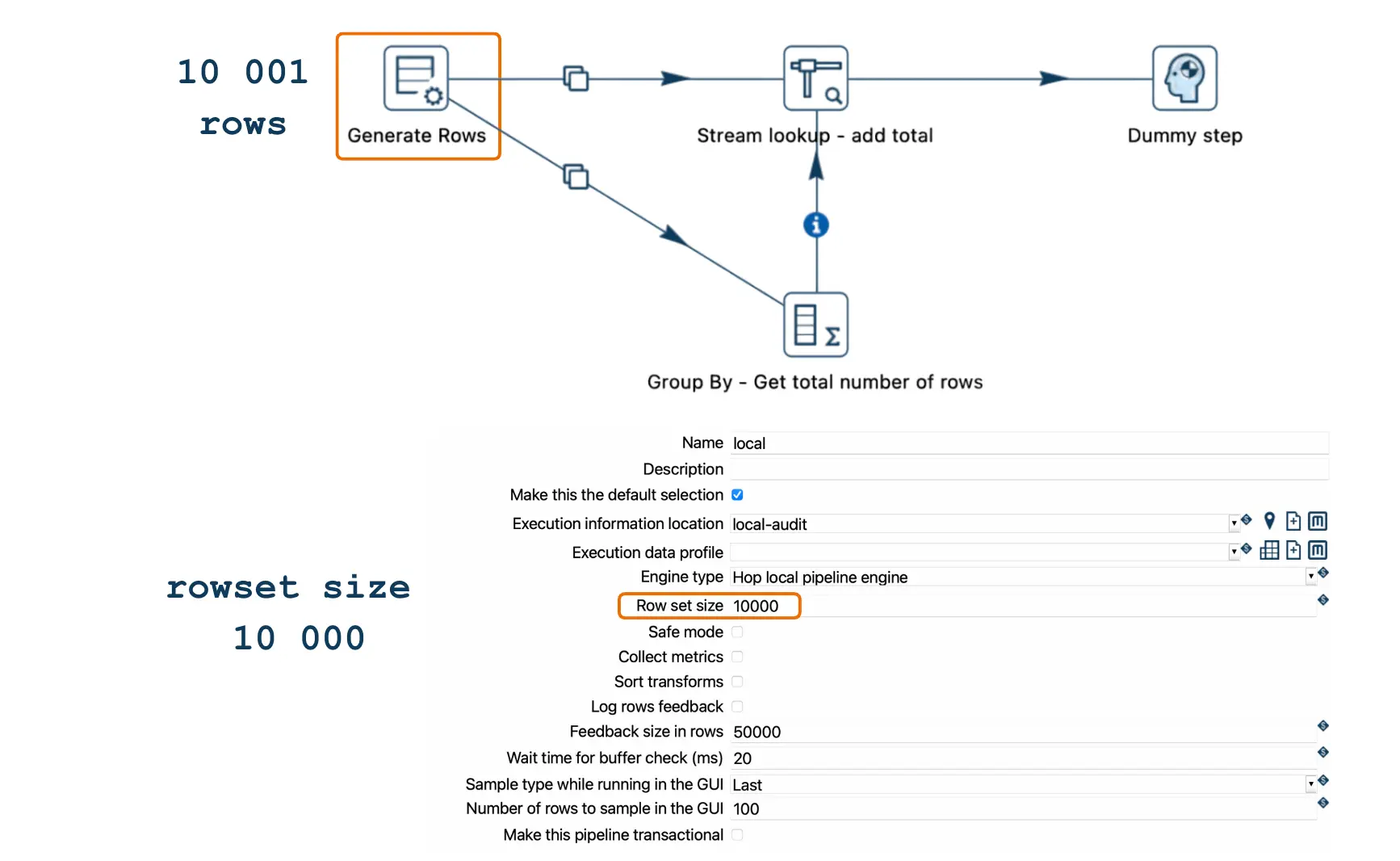
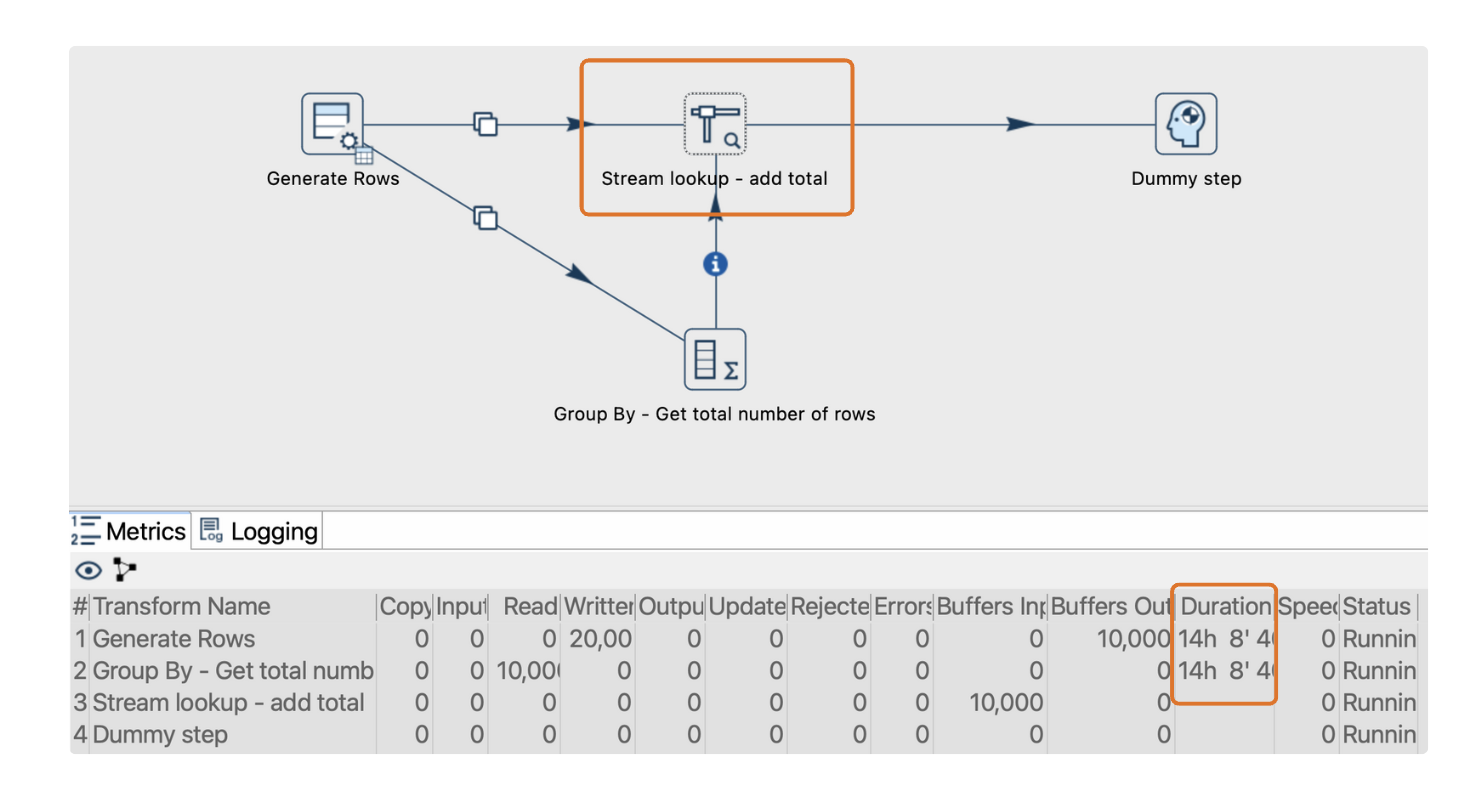
Un bloqueo puede ocurrir cuando el número de filas procesadas excede la capacidad del búfer entre transformaciones, definida por la configuración de tamaño de fila (Rowset size). En Apache Hop, cada "hop" (enlace de datos entre transformaciones) tiene un búfer limitado basado en el tamaño de fila. Por defecto, este tamaño suele ser de 10,000 filas, lo que significa que un hop puede almacenar temporalmente hasta 10,000 filas entre transformaciones.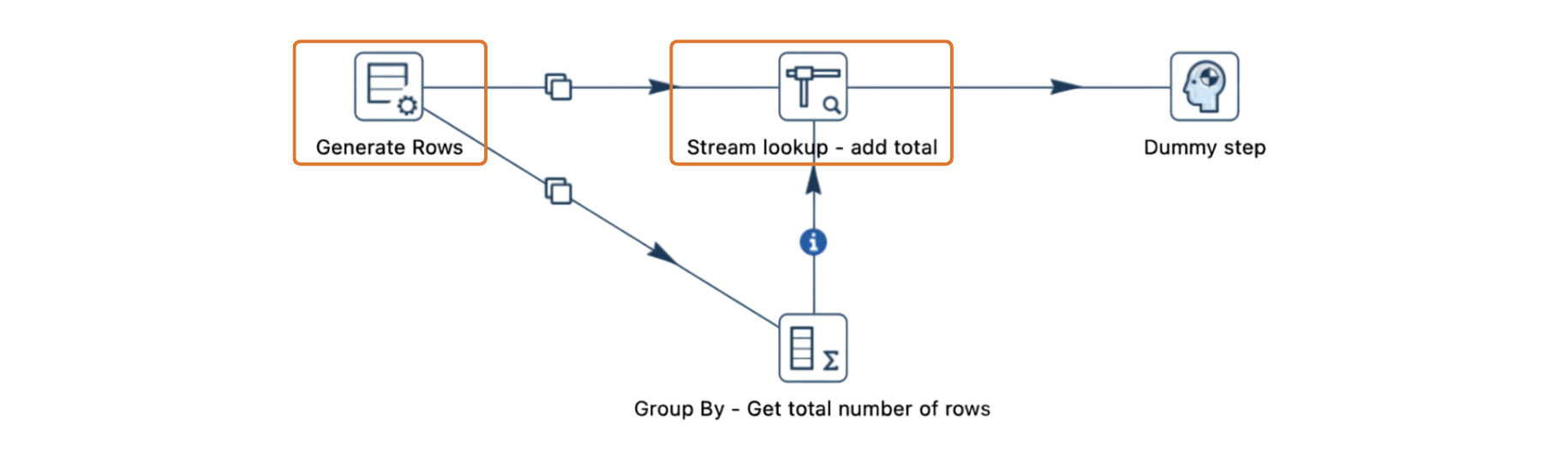
Imagina un pipeline donde los datos fluyen desde una transformación "Generate Rows", se dividen en dos flujos y luego se vuelven a combinar en la transformación "Stream lookup".
- Un flujo llega directamente a "Stream lookup", mientras que el otro pasa por una transformación intermedia, como "Group By".
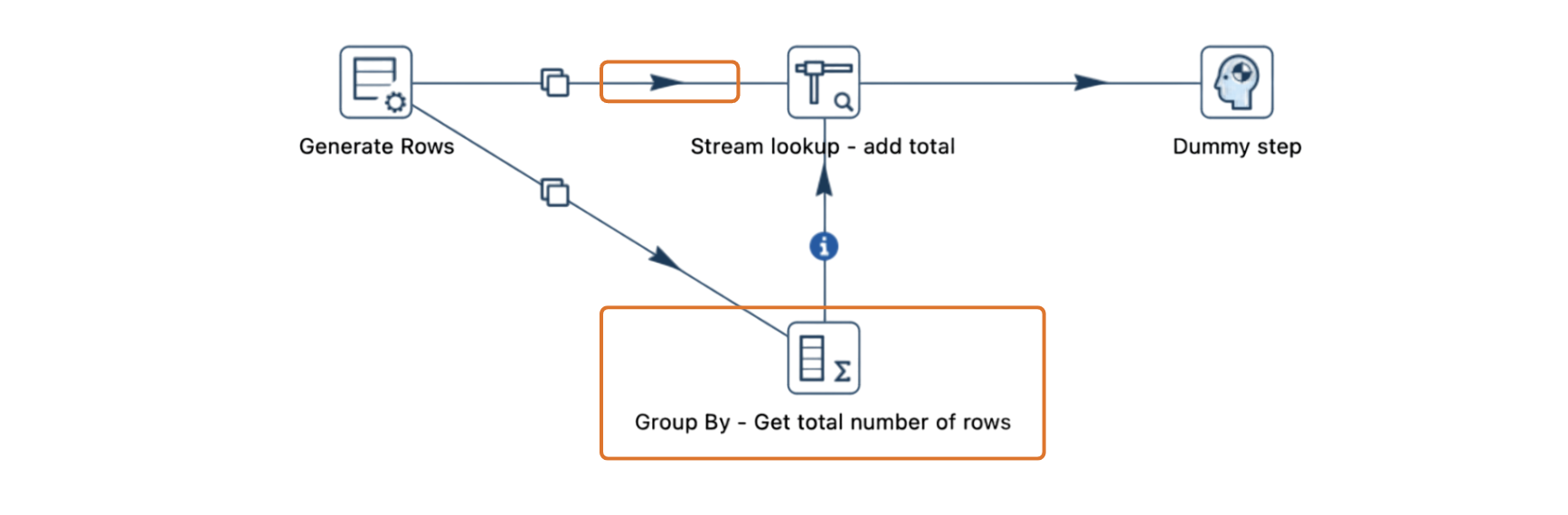
- Si se generan 10,001 filas y el tamaño del búfer está configurado en 10,000, el pipeline se detiene cuando el búfer alcanza su capacidad.
- Si "Stream lookup" está esperando datos de ambos flujos y uno tiene un búfer lleno, ninguno de los flujos puede continuar, lo que detiene completamente el pipeline.
Soluciones para evitar bloqueos
1. Ajustar el tamaño de fila (con precaución)
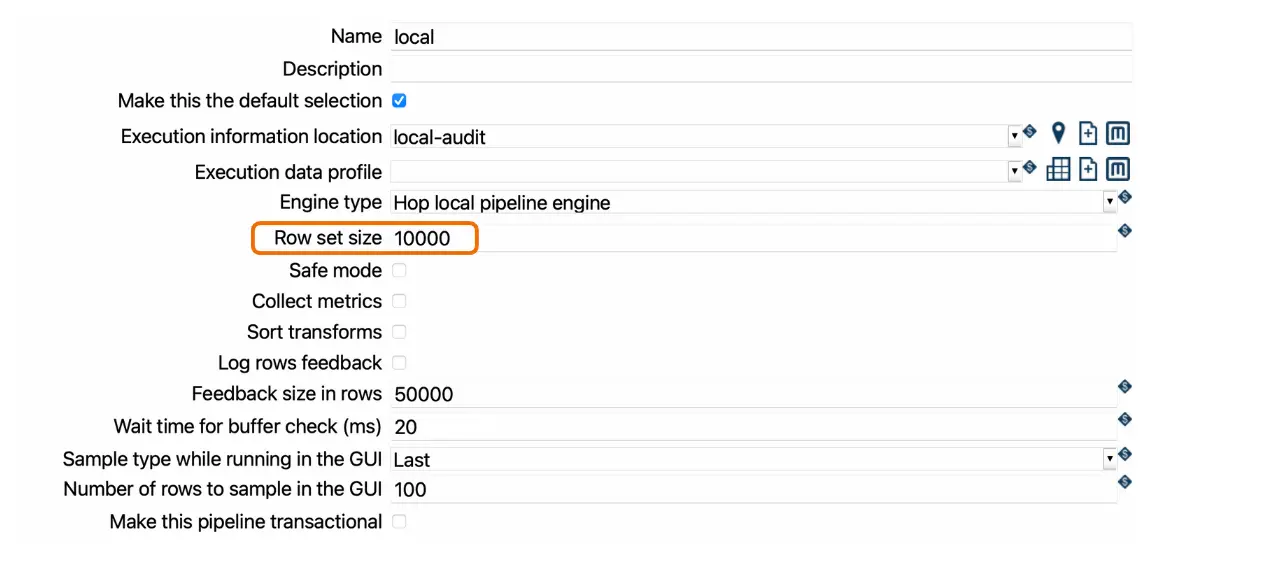
Incrementar el tamaño de fila puede ser una solución temporal al permitir que se almacenen más filas en el búfer. Sin embargo, esto debe hacerse con cuidado, ya que a medida que los volúmenes de datos crecen, un tamaño mayor podría aumentar el uso de memoria y empeorar el rendimiento a largo plazo.
Puntos clave:
- El tamaño de fila determina las filas almacenadas temporalmente entre transformaciones.
- Por defecto, se configura en 10,000 filas, pero puede personalizarse según el volumen de datos y la estructura del pipeline.
- Si usas un motor local en la configuración del pipeline, puedes modificar el tamaño de fila.
2. Separar los flujos de entrada
Otra solución es dividir los flujos de datos en dos copias paralelas. Cada flujo puede realizar sus operaciones de forma independiente, evitando los bloqueos causados por transformaciones que generan cuellos de botella en un solo flujo.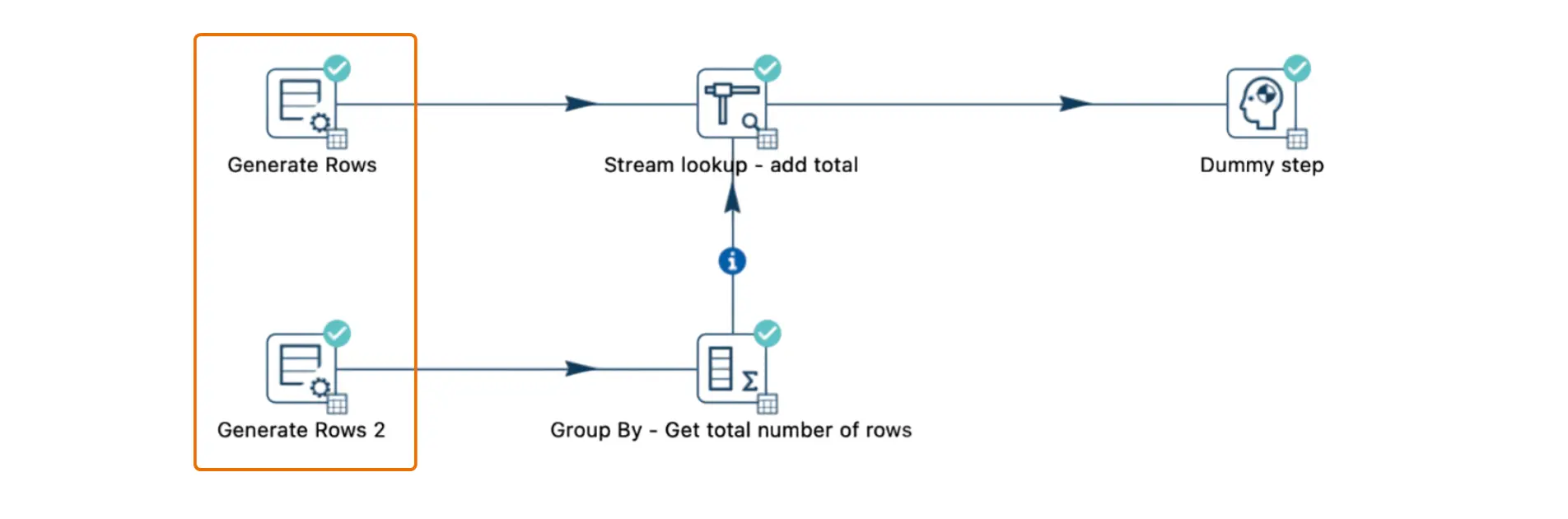
3. Dividir el pipeline en unidades más pequeñas
Separar el pipeline en etapas más pequeñas permite procesar los datos en secciones. Los datos intermedios se pueden escribir en tablas o archivos temporales, permitiendo que cada etapa finalice sin depender de las demás. Esto es particularmente efectivo para evitar bloqueos relacionados con búferes en pipelines complejos.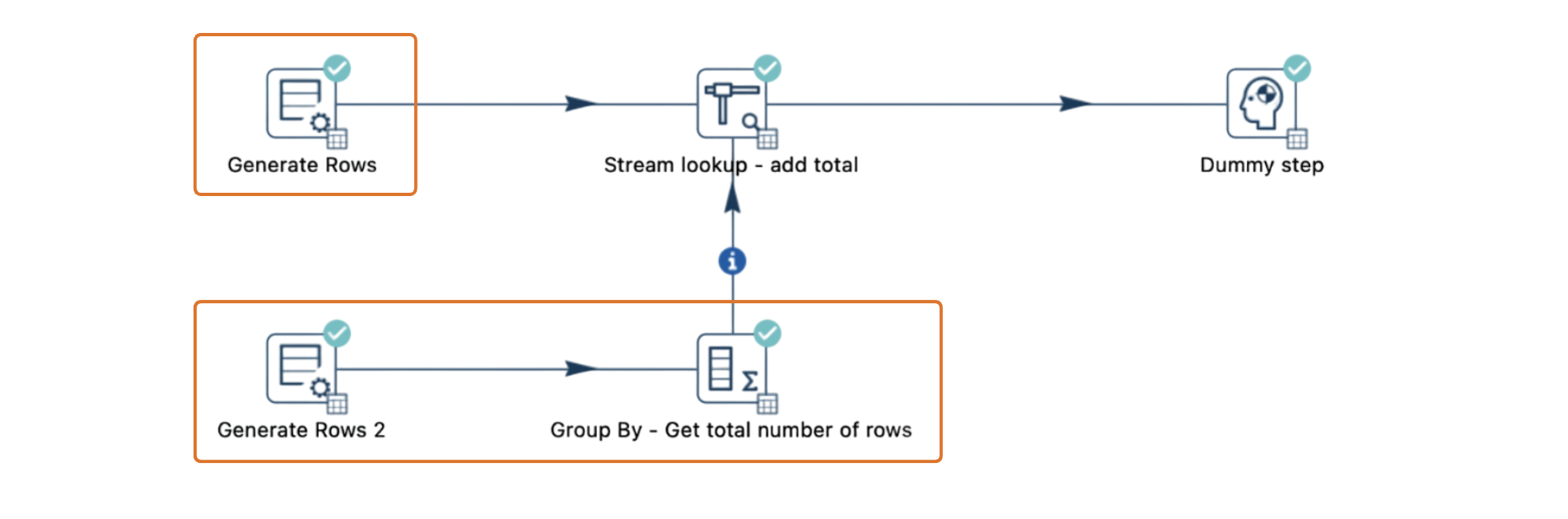
4. Usar la transformación "Blocking"
Para pipelines que requieren procesamiento secuencial, la transformación "Blocking" puede ser una herramienta útil.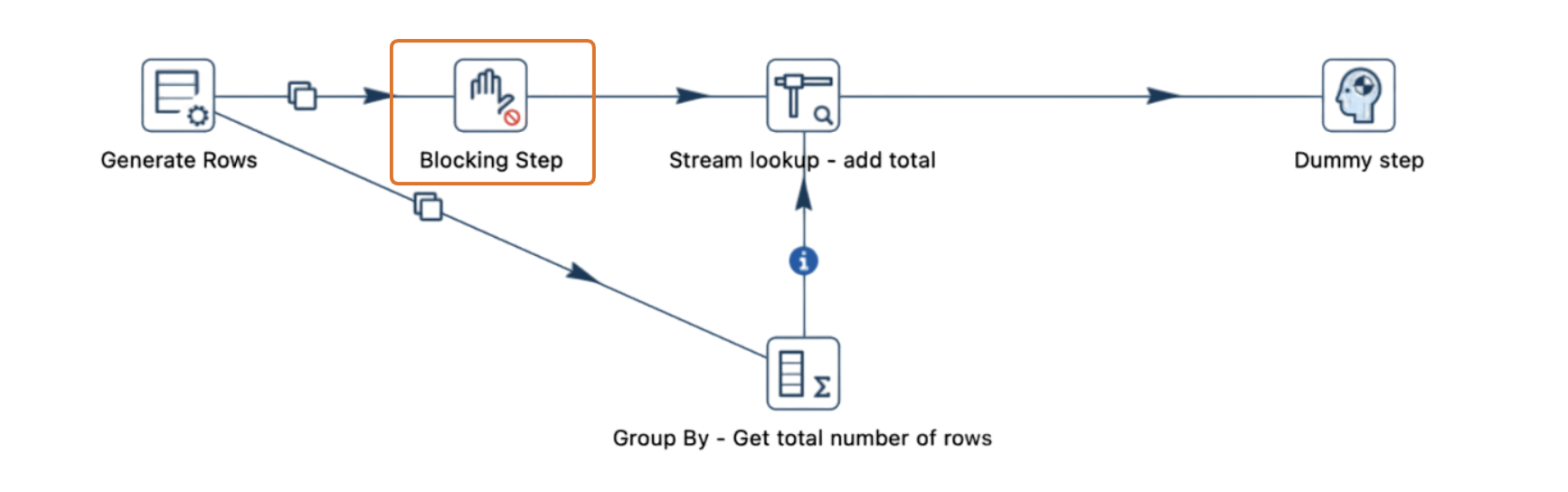
Configura "Blocking" con la opción “Pass all rows” para asegurarte de que todas las filas en un flujo se procesen completamente antes de pasar a la siguiente transformación. Ajusta configuraciones como el tamaño de caché en la transformación "Blocking" para optimizar el rendimiento según tus necesidades.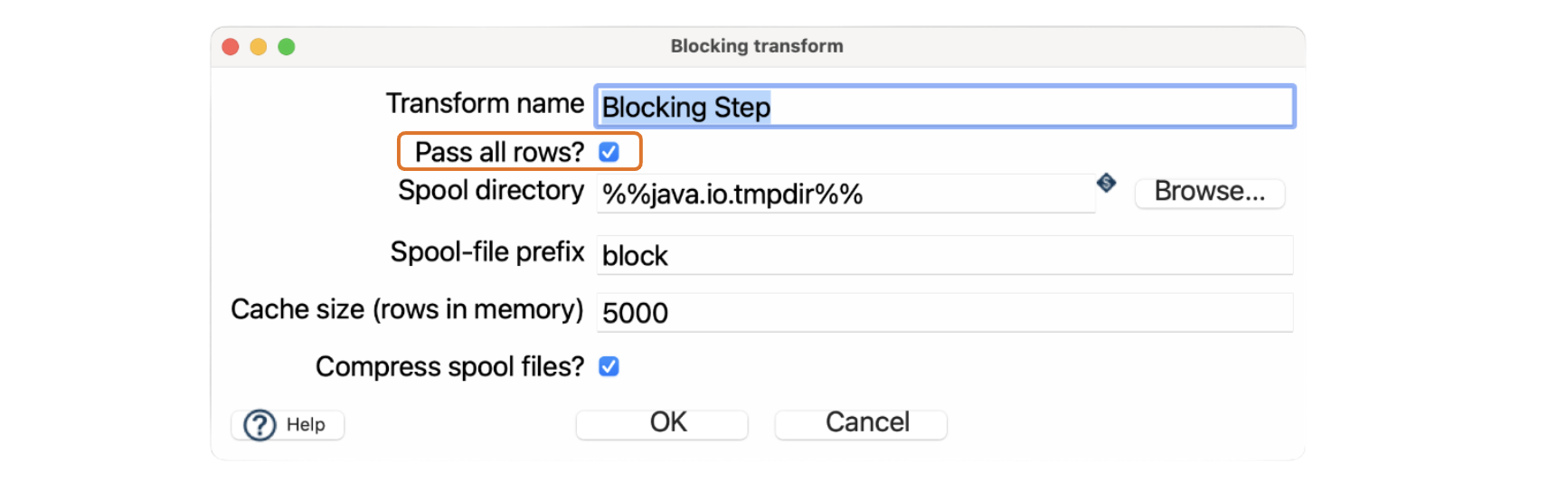
Conclusiones clave
- Los pipelines con la transformación "Stream lookup" son propensos a bloqueos al procesar grandes conjuntos de datos.
- El tamaño de fila (Rowset size) determina la cantidad máxima de filas almacenadas entre transformaciones. Establecer un tamaño adecuado es esencial para gestionar el flujo de datos.
- Las soluciones prácticas incluyen dividir flujos, separar pipelines en etapas más pequeñas y usar la transformación "Blocking" para manejar datos de manera secuencial.

