

Esta publicación se basa en el contenido cubierto en la publicación anterior (Ejecución de...
Al decidir entre pipelines y workflows en tu implementación, el enfoque básico se reduce a lo siguiente:
Pipelines: Utiliza pipelines principalmente para tareas de transformación de datos. Los pipelines son la columna vertebral del procesamiento de datos, responsables de leer, modificar, enriquecer, limpiar y escribir datos. Actúan como los caballos de batalla de tus tareas de procesamiento de datos y pueden ser orquestados a través de otros pipelines o workflows.
Workflows: Por otro lado, los workflows son excelentes para orquestar pipelines y otros workflows. Son secuencias de operaciones que generalmente se ejecutan de forma secuencial, aunque pueden soportar la ejecución paralela si es necesario. Los workflows se centran menos en la manipulación directa de datos y más en tareas de orquestación generales, como la ejecución de archivos, verificaciones de infraestructura, notificaciones por correo electrónico, manejo de errores, entre otros.
Sin embargo, la decisión entre pipelines y workflows no siempre es sencilla. Depende de los requisitos específicos y varía según el escenario. Comprender los comportamientos de ejecución predeterminados (pipelines que se ejecutan en paralelo y workflows que se ejecutan secuencialmente) es crucial para tomar la decisión correcta.
Exploremos algunos escenarios que demuestran cuándo un workflow podría ser una mejor opción que un pipeline.
Escenario #1
Tienes un pipeline diseñado para manejar datos de actores almacenados en una tabla de PostgreSQL. El proceso implica filtrar datos para el año 2024, ya que cada nuevo actor en 2024 requiere procesamiento de archivos por separado. Después de filtrar, cada archivo se procesa utilizando una transformación de ejecución de pipeline donde los datos se extraen y cargan en una nueva tabla. Posteriormente, los datos procesados se extraen nuevamente y ciertos metadatos se cargan en una tabla de metadatos separada.
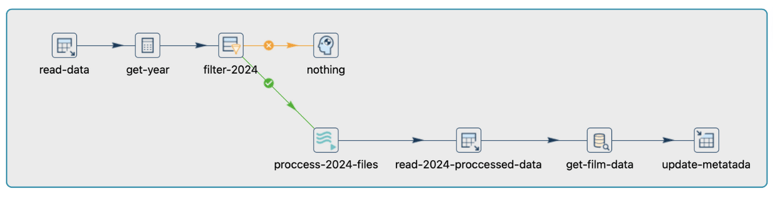
En este pipeline, hay dos momentos distintos que son cruciales: primero, el procesamiento de datos para el año 2024, y luego la extracción posterior al procesamiento, utilizada para fines de metadatos.
¿Por qué es incorrecto este pipeline?
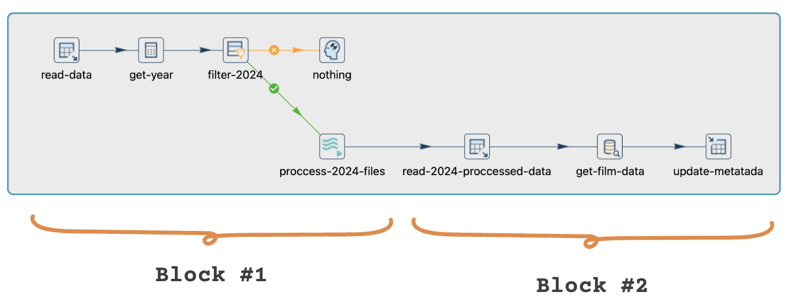
Este pipeline es incorrecto porque no aborda la naturaleza secuencial de las tareas involucradas. Cada transformación comienza simultáneamente, lo que puede llevar a problemas cuando una tarea depende de la finalización de otra. En escenarios donde ciertas operaciones deben ejecutarse en un orden específico, como extraer datos después de haber sido procesados, este enfoque de ejecución simultánea es inadecuado y puede resultar en inconsistencias o errores en los datos.
Dado el inicio simultáneo de todas las transformaciones en este pipeline, es imperativo que el bloque inicial se ejecute primero. Intentar extraer datos procesados antes de que se carguen resultaría en una salida nula.
He encontrado errores como este varias veces. Es importante entender cómo se ejecutan los pipelines y las métricas de ejecución. Dependiendo del orden deseado de las transformaciones de datos, puede que necesites elegir entre pipelines o workflows.
Solucionar esto
Para abordar este problema, debemos asegurarnos de que el pipeline ejecute las tareas en la secuencia correcta. Podemos lograr esto reestructurando el pipeline o empleando una combinación de pipelines y workflows.
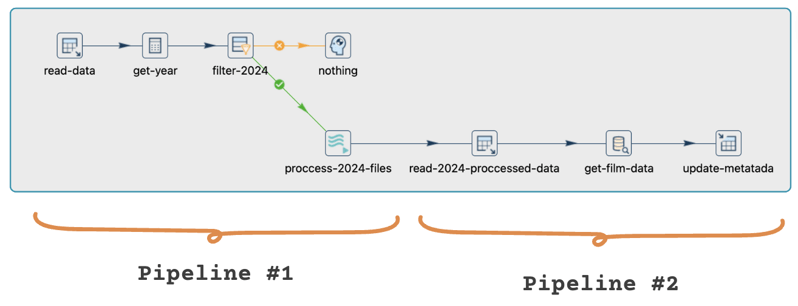
Específicamente, debemos diseñar la implementación para ejecutar cada bloque de manera secuencial, asegurando que el procesamiento y la extracción de datos ocurran en el orden requerido.
Pipeline #1:
El primer pipeline maneja la extracción, filtrado y procesamiento de archivos.
Pipeline #2:
El segundo pipeline extrae los datos procesados y carga los metadatos en una tabla separada.
Workflow:
Adicionalmente, podemos usar un workflow para orquestar la ejecución de múltiples pipelines, permitiendo un control más preciso sobre la secuencia de tareas y dependencias.

Escenario #2
Tienes una serie de tareas donde necesitas ejecución secuencial. Por ejemplo, comienzas con la ejecución de una consulta SQL para truncar una tabla, seguido de leer y escribir en otra tabla, y finalmente ejecutar otra consulta SQL.

¿Por qué es incorrecto este pipeline?
Este pipeline es incorrecto porque todas las transformaciones comenzarán simultáneamente, mientras que en este escenario, necesitamos que se ejecuten en un orden específico.
Como resultado, no podemos controlar la secuencia de ejecución de las transformaciones. Si necesitamos que la transformación truncate-table se ejecute primero, seguida del bloque de lectura-escritura (read-data y bulk-load), y finalmente la transformación de eliminar datos, la ejecución paralela predeterminada en los pipelines no cumplirá con nuestros requisitos.
En tales casos, donde la ejecución paralela predeterminada no se alinea con nuestras necesidades, implementar un workflow podría ser más apropiado. Un workflow nos permite definir una secuencia de acciones a ser ejecutadas una tras otra. En este escenario, iniciaríamos el workflow con la ejecución de la consulta SQL, seguida de un pipeline que maneje las tareas de entrada y salida de tablas, y concluyendo con la ejecución de la consulta SQL final.
Solucionar esto
Podemos rectificar este problema usando una combinación de workflows y pipelines en lugar de depender únicamente de un pipeline. Así es como:
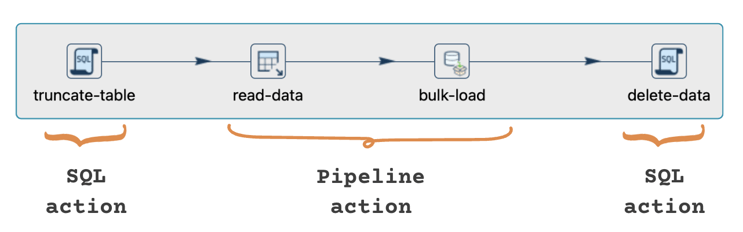
- Crea un workflow donde primero se ejecute la operación de truncar.
- Ejecuta un sub-pipeline dentro del workflow, que contenga las transformaciones de lectura y escritura.
- Finalmente, ejecuta la operación de eliminar.
Este enfoque asegura que los tres bloques se ejecuten secuencialmente, cumpliendo con los requisitos específicos de nuestro escenario.

Este enfoque también asegura que si algo falla en cualquier etapa de la ejecución, el proceso se detendrá, permitiéndote solucionar problemas de manera efectiva. Aunque este es un ejemplo simplificado, los workflows ofrecen acciones como "Check DB connection" para comprobar la conectividad y registrar los resultados de la ejecución para la resolución de errores si es necesario.

