


.png)


Importa datos relacionales en Neo4j utilizando Apache Hop con nuestra guía dedicada de Salida a...
Descubre el potencial de los Objetos de Metadatos en Apache Hop a través de este post - Parte II. Aprovecha el poder de los metadatos para una integración de datos más eficiente.
Introducción
El uso de objetos de metadatos en los procesos de integración de datos se ha vuelto cada vez más importante en los últimos años, y Apache Hop no es una excepción. Con los objetos de metadatos, los usuarios pueden gestionar y mantener fácilmente complejas canalizaciones de datos y tareas de procesamiento, definiendo y estandarizando definiciones de datos, información de conexión y reglas de procesamiento en diferentes flujos de trabajo y canalizaciones.
En Apache Hop, los objetos de metadatos se utilizan para almacenar y gestionar información sobre las fuentes de datos, los destinos y otros componentes de un proceso de integración de datos. Los objetos de metadatos sirven como un repositorio central para la configuración y la información de conexión que se puede compartir en diferentes (pipelines) canalizaciones y (workflows) flujos de trabajo, lo que facilita la gestión y el mantenimiento de procesos complejos de integración de datos.
Existen muchos tipos diferentes de objetos de metadatos en Apache Hop, que incluyen (database connections) conexiones de bases de datos, (file formats) formatos de archivo, (file definitions) definiciones de archivos, (run configurations) configuraciones de ejecución, etc. Estos objetos se definen utilizando la interfaz gráfica de usuario de Hop (Hop GUI), que permite a los usuarios crear, editar y gestionar objetos de metadatos sin necesidad de escribir ningún código.
.png)
Uno de los principales beneficios de utilizar objetos de metadatos en Apache Hop es que permiten a los usuarios definir y gestionar conexiones a una amplia variedad de fuentes de datos y destinos, incluyendo bases de datos, sistemas de archivos y más. Esto facilita la integración de datos procedentes de diferentes fuentes y la realización de tareas complejas de canalizaciones y procesamiento de datos.
Aquí tienes un resumen de los temas que se tratarán en la publicación sobre objetos de metadatos en Apache Hop:
-
La importancia de los objetos de metadatos en Apache Hop para (workflows) flujos de trabajo y (pipelines) canalizaciones.
-
Los diferentes tipos de objetos de metadatos disponibles en Apache Hop, las relaciones/dependencias entre algunos de ellos y sus casos de uso.
-
Los beneficios de utilizar objetos de metadatos en Apache Hop para el procesamiento de datos, la colaboración y la eficiencia.
-
Instrucciones paso a paso y capturas de pantalla para crear y gestionar algunos objetos de metadatos utilizando la interfaz gráfica de usuario de Apache Hop.
-
Mejores prácticas para utilizar objetos de metadatos en Apache Hop y optimizar (workflows) flujos de trabajo de integración de datos.
En esta publicación de dos partes, exploraremos el poder de los objetos de metadatos en Apache Hop, cubriendo los diferentes tipos de objetos disponibles, sus beneficios, casos de uso e instrucciones paso a paso para crear y gestionarlos utilizando la interfaz gráfica de usuario de Hop (Hop GUI). En esta segunda publicación, abordaremos objetos de metadatos esenciales, incluyendo Conexiones de Base de Datos Relacionales, Conexiones de Neo4j, Modelos de Gráficos de Neo4j, Conexiones de MongoDB y más.
Al final de esta serie, los lectores tendrán una comprensión integral de los objetos de metadatos en Apache Hop y las mejores prácticas para utilizarlos eficazmente en (workflows) flujos de trabajo de integración de datos.
Consulte la primera publicación: El Poder de los Objetos de Metadatos en Apache Hop: Una Guía Integral I.
Cómo Crear y Gestionar Objetos de Metadatos en Apache Hop
Existen varias formas de crear y gestionar objetos de metadatos mediante la interfaz gráfica de usuario de Apache Hop (Hop GUI). Dependerá del tipo de metadatos, pero en esta publicación, cubriremos dos de ellas.
Primera
-
Abre el Apache Hop GUI y selecciona la (Metadata) perspectiva de Metadatos.

-
Selecciona un tipo de objeto de metadatos y haz clic en el botón (New) Nuevo.
-
Rellena los detalles del objeto de metadatos, como los detalles de conexión para una (database connections) conneción de base de datos o la (file definition) definición de archivo.
-
Haz clic en (OK) Aceptar para guardar el objeto de metadatos.
Segunda
-
Abre la interfaz gráfica de usuario de Apache Hop y haz clic en Hop->New o en el botón (New) Nuevo visible en el menú horizontal.

-
Selecciona el tipo de objeto de metadatos que deseas crear en el menú contextual. Esto te llevará a la (Metadata) perspectiva de Metadatos y se abrirá el diálogo con los campos que deben completarse.

-
Completa los detalles del objeto de metadatos, como los detalles de conexión para una (database connections) conneción de base de datos o la (file definition) definición de archivo.
-
Haz clic en (OK) Aceptar para guardar el objeto de metadatos.
Una vez que hayas creado un objeto de metadatos, puedes utilizarlo en tus (workflows) flujos de trabajo y (pipelines) canalizaciones haciendo referencia a él en la (action) acción o (transform) transformación adecuada.
Para gestionar los objetos de metadatos, puedes utilizar la perspectiva de Metadatos para ver, editar o eliminar objetos existentes.
Tipos de Metadatos en Apache Hop
Apache Hop proporciona una variedad de objetos de metadatos que los usuarios pueden crear y gestionar para optimizar el proceso de integración de datos. Hasta ahora (Apache Hop 2.4), los tipos de objetos de metadatos en Apache Hop son:
- Pipeline Run Configuration (Configuración de Ejecución de Canalización)
-
Execution Information Location (Ubicación de la Información de Ejecución)
-
Execution Data Profile (Perfil de Datos de Ejecución)
-
Workflow Run Configuration (Configuración de Ejecución de Flujo de Trabajo)
-
Pipeline Log (Registro de Pipeline)
-
Workflow Log (Registro de Flujo de Trabajo)
-
Pipeline Probe (Sonda de Pipeline)
-
Pipeline Unit Test (Prueba Unitaria de Pipeline)
-
Data Set (Conjunto de Datos)
-
Beam File Definition (Definición de Archivo Beam)
-
Relational Database Connection (Conexión a Base de Datos Relacional)
-
Neo4j Connection (Conexión a Neo4j)
-
Neo4j Graph Model (Modelo de Gráfico de Neo4j)
-
MongoDB Connection (Conexión a MongoDB)
-
Cassandra Connection (Conexión a Cassandra)
-
Splunk Connection (Conexión a Splunk)
-
Partition Schema (Esquema de Partición)
-
Hop Server (Servidor Hop)
-
Web Service (Servicio Web)
-
Asynchronous Web Service (Servicio Web Asincrónico)
Nota: En este post, los nombres de los principales términos técnicos se mantendrán en inglés y en español para facilitar su comprensión y referencia en la documentación oficial.
Si, hay varios objetos de metadatos que debemos cubrir, lo cual es una excelente noticia. No hay necesidad de preocuparse, ya que te guiaremos a través de cada uno de ellos, proporcionaremos ejemplos y aclararemos las dependencias entre algunos de ellos. Este es el primero de dos posts donde cubriremos todos los objetos de metadatos actuales en Apache Hop. Este primer post incluirá los siguientes objetos de metadatos:
-
Relational Database Connection (Conexión a Base de Datos Relacional)
-
Neo4j Connection (Conexión a Neo4j)
-
Neo4j Graph Model (Modelo de Gráficos de Neo4j)
-
MongoDB Connection (Conexión a MongoDB)
-
Cassandra Connection (Conexión a Cassandra)
-
Splunk Connection (Conexión a Splunk)
-
Partition Schema (Esquema de Partición)
-
Hop Server (Servidor Hop)
-
Web Service (Servicio Web)
-
Asynchronous Web Service (Servicio Web Asíncrono)
Relational Database Connection
El objeto de metadatos de Conexión a Base de Datos Relacional en Apache Hop se utiliza para definir conexiones a bases de datos relacionales, como MySQL, Oracle, PostgreSQL, SQL Server y más. Este objeto de metadatos proporciona una forma de configurar los parámetros necesarios para conectarse a una base de datos específica, como el nombre del host, el puerto, el nombre de la base de datos, el nombre de usuario y la contraseña.
Al crear una nueva Conexión a Base de Datos Relacional en Apache Hop, se le solicita al usuario que ingrese la información necesaria para la base de datos a la que desean conectarse, pero esto depende del tipo de base de datos. Puede crear una conexión genérica o utilizar uno de los varios tipos de bases de datos ofrecidos por Apache Hop para establecer una conexión con una base de datos.
Por ejemplo, si elige PostgreSQL como su tipo de conexión, aparecerán los siguientes campos:
-1.png)
- Connection type (Tipo de conexión): Select a connection type to be used.
- Installed driver (Controlador instalado): It specifies the version of the installed driver class. This is informative only.
- Username (Nombre de usuario): Set the username you use to connect to the database.
- Password (Contraseña): Add the password you use to connect to the database.
- Server host name (Nombre del host del servidor): Set the database server host.
- Port number (Número de puerto): Add the port to connect to the database.
- Database name (Nombre de la base de datos): Set the database name for the connection.
- Manual connection URL (URL de conexión manual): You could also configure a manual connection URL instead, in the format postgres://{user}:{password}@{hostname}:{port}/{database-name}
Después de que se ha establecido la conexión, el usuario puede hacer referencia a ella de manera sencilla en otros componentes, como las transformaciones Table Input o Table Output, para leer o escribir datos desde la base de datos especificada.
El uso del objeto de metadatos Relational Database Connections permite una gestión más eficiente y estandarizada de las conexiones a bases de datos en Apache Hop.
Al definir una conexión una vez y utilizarla en todo el flujo de trabajo, el usuario puede evitar duplicar la información de conexión y asegurar la consistencia en cómo se utiliza la conexión en diferentes componentes.
Además, el objeto de metadatos permite una actualización sencilla de la información de conexión si es necesario, sin tener que actualizar manualmente cada componente que utiliza la conexión.
Neo4j Connection
El objeto de metadatos Neo4j Connection en Apache Hop permite a los usuarios conectarse a una base de datos de grafo Neo4j. Este objeto de metadatos contiene la información necesaria para establecer una conexión, como el host, el puerto, el nombre de usuario y la contraseña. Además, los usuarios pueden especificar opciones adicionales, como la encriptación y la estrategia de confianza.
Pestaña Básica (Basic)

- Connection name (Nombre de conexión): Especifica el nombre del objeto de metadatos.
- Protocol (Protocolo): El protocolo por defecto es neo4j. Para conectarse a una base de datos de Aura versión 4 o 5, se puede usar el protocolo neo4j+s.
- Server or IP address (Nombre del servidor o dirección IP): Configura el nombre del servidor Neo4j.
- Database name (Nombre de la base de datos): Especifica el nombre de la base de datos Neo4j que se va a utilizar.
- Database port (Puerto de la base de datos): Especifica el número de puerto.
- Username (Nombre de usuario): Especifica tu nombre de usuario para conectarte al servidor Neo4j.
- Password (Contraseña): Especifica tu contraseña para conectarte al servidor Neo4j.
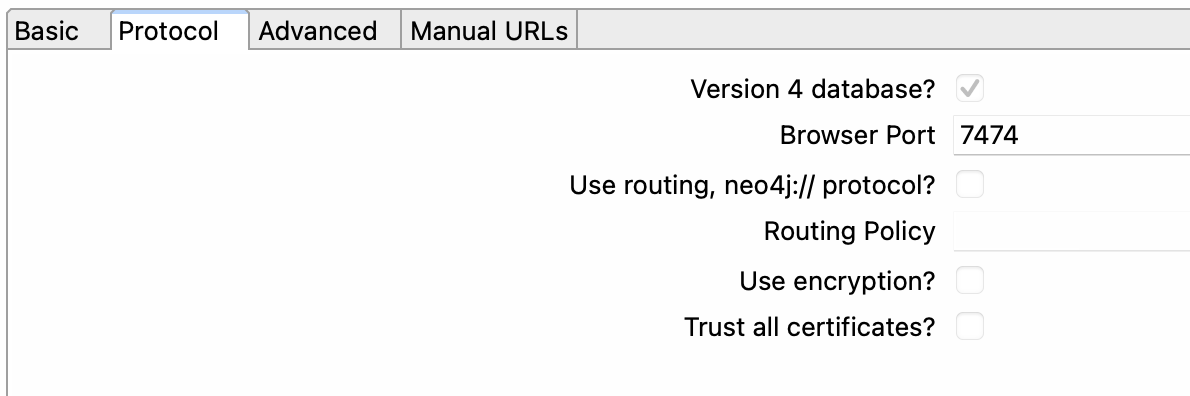
- Version 4 database (Base de datos de versión 4): Habilita esta opción para ayudarnos a generar el Cypher más optimizado para ti.
- Browser port (Puerto del navegador): Solo información. Especifica el puerto en el que se ejecuta el navegador Neo4j.
- Use routing, neo4j:// protocol (Usar enrutamiento, protocolo neo4j://): Para utilizar el protocolo bolt+routing, selecciona esta opción para habilitarla.
- Routing policy (Política de enrutamiento): Especifica la política de enrutamiento bolt+routing a usar.
- Use encryption (Usar encriptación): Desactiva esta opción a menos que hayas generado y configurado las claves SSL apropiadas.
Pestaña Avanzado (Advanced)
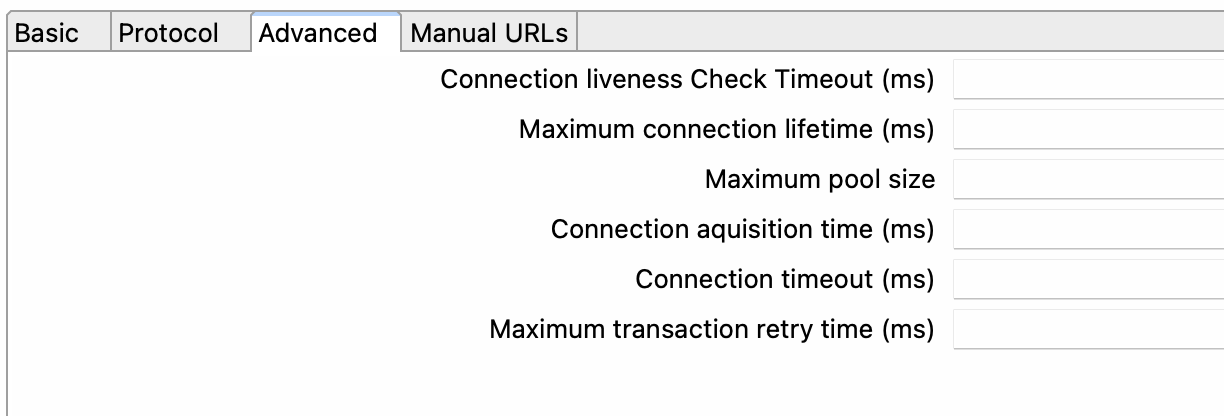
-
Connection Liveliness Check Timeout (ms) (Tiempo de espera para comprobar la vitalidad de la conexión en milisegundos): Establece un equilibrio entre los problemas de conexión y el rendimiento al verificar las conexiones en el grupo que han estado inactivas durante demasiado tiempo. El valor predeterminado es 0.
-
Maximum Connection Lifetime (ms) (Tiempo máximo de vida de la conexión en milisegundos): Cierra las conexiones en el grupo que han estado activas durante más tiempo que este límite para evitar una alta rotación de conexiones. El valor predeterminado es 1 hora.
-
Maximum Pool Size (Tamaño máximo del grupo de conexiones): Limita la cantidad máxima de conexiones en el grupo. El valor predeterminado es 100.
-
Connection Acquisition Time (ms) (Tiempo de adquisición de la conexión en milisegundos): Establece el tiempo máximo para los intentos de adquisición de conexión. El valor predeterminado es 60 segundos.
-
Connection timeout (ms) (Tiempo de espera de conexión en milisegundos): Esta opción establece el tiempo máximo que el controlador esperará para que se establezca una conexión con la base de datos antes de generar un error.
-
Maximum Transaction Retry Time (ms) (Tiempo máximo de reintentos de transacción en milisegundos): Especifica el tiempo máximo para que las transacciones se vuelvan a intentar. El valor predeterminado es de 30 segundos.
Pestaña URLs Manuales (Manual URLs)
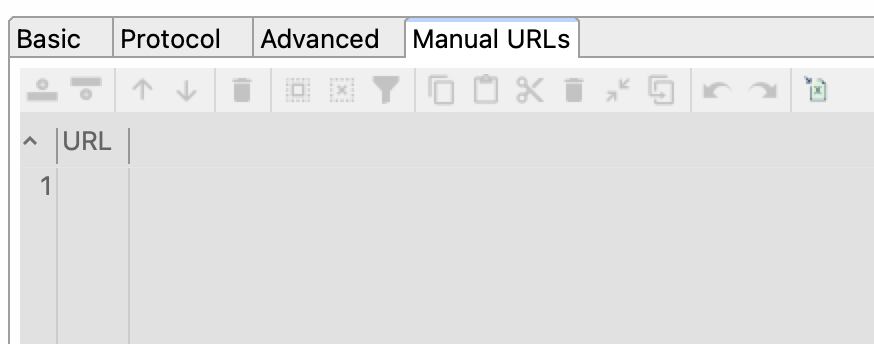
-
Manual URLs (URLs Manuales): Especifique una lista de URL de conexión manual para trabajar con funciones avanzadas.
Una vez que se crea el objeto de metadatos de Conexión Neo4j, se puede utilizar en transformaciones de Apache Hop para leer o escribir datos en la base de datos Neo4j conectada.
Por ejemplo, la transformación Neo4j Cypher permite a los usuarios especificar el objeto de metadatos de Conexión Neo4j, así como la consulta o declaración a ejecutar en la base de datos.
También es posible utilizar acciones en (workflows) flujos de trabajo para verificar conexiones a Neo4j, ejecutar scripts de Neo4j y actualizar restricciones o índices.
En futuras publicaciones, cubriremos la lista completa de complementos de Apache Hop para Neo4j.
Neo4j Graph Model
El objeto de metadatos de Modelo de Gráfico Neo4j en Apache Hop proporciona una forma de definir y gestionar metadatos para una base de datos de gráficos Neo4j. El objeto de metadatos de Modelo de Gráfico Neo4j consta de dos componentes principales: nodos y relaciones.
Los nodos se definen mediante etiquetas que describen los nodos. Las etiquetas representan los nodos en el gráfico, y cada etiqueta puede tener uno o más atributos asociados.
Los atributos se definen como pares de clave-valor, donde la clave es el nombre del atributo y el valor es el tipo de datos del atributo.
Las relaciones representan las conexiones entre los nodos en el gráfico, y cada relación puede tener uno o más atributos asociados. Al igual que las etiquetas, los atributos de las relaciones se definen como pares de clave-valor.
Puede definir un Modelo de Gráfico Neo4j en Apache Hop como un objeto de metadatos. Un modelo de gráfico en Apache Hop le permite crear nodos con sus atributos, así como las conexiones o relaciones entre estos nodos.
A continuación, se muestra un ejemplo de cómo se configura un modelo de gráfico.
Pestaña Modelo (Model)
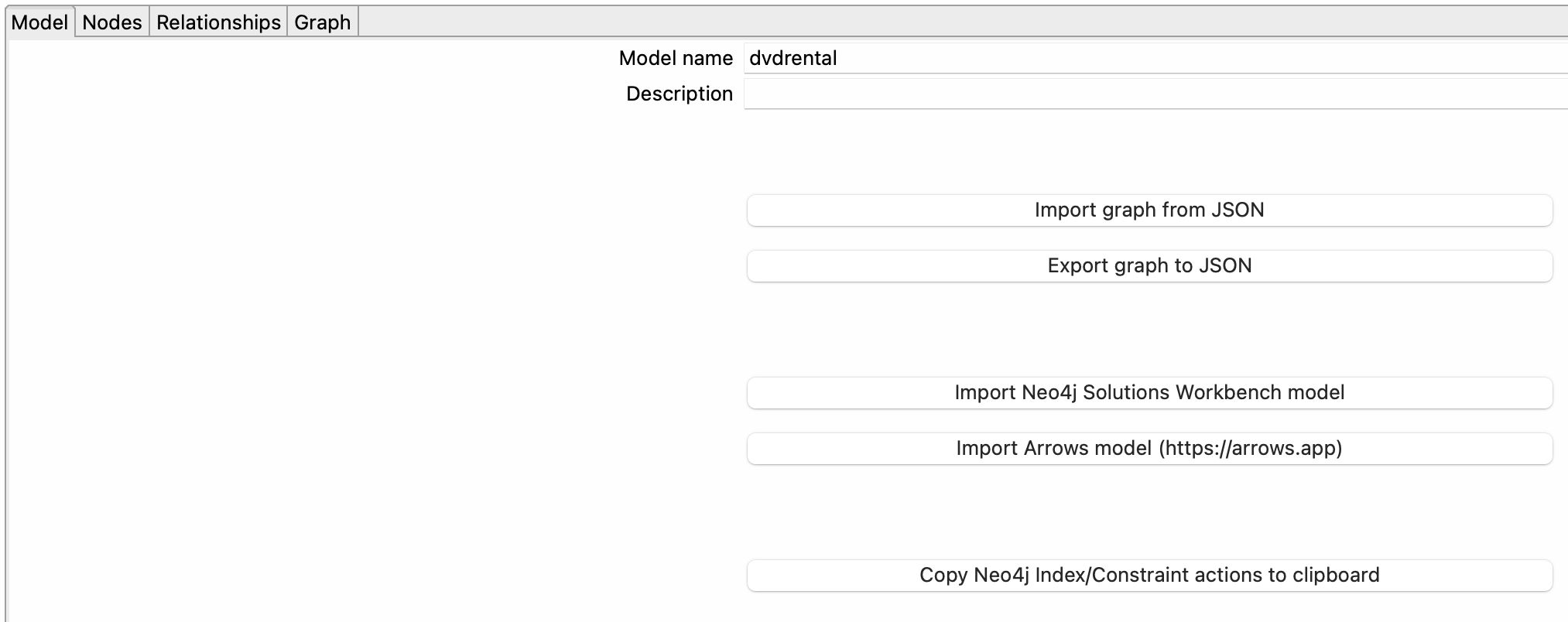
- En la pestaña "Modelo", establece el nombre del modelo de gráfico: dvdrental.
Pestaña Nodos (Nodes)
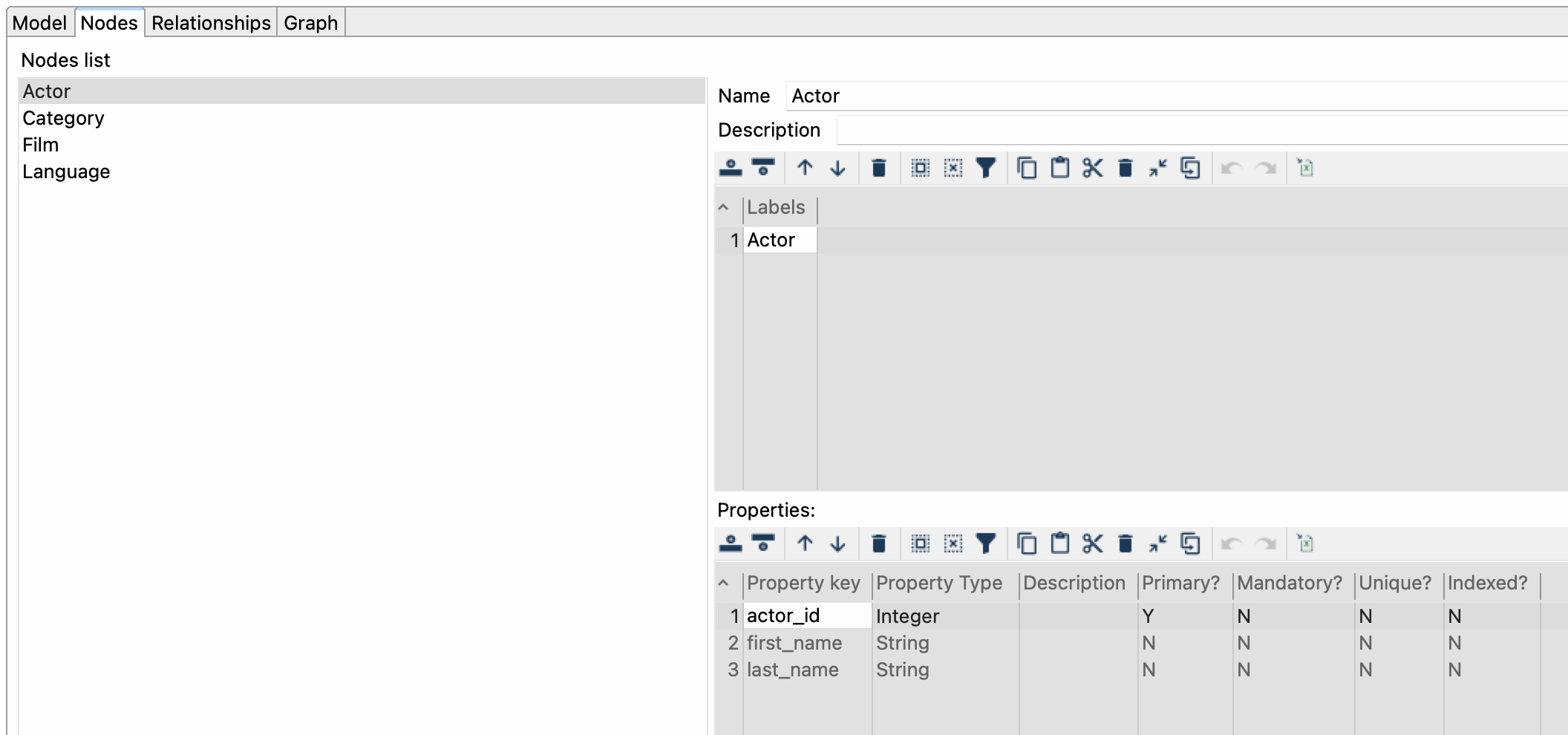
- Agrega las etiquetas: Actor en este caso, y las propiedades: actor_id, last_name, first_name.
- Especifica la clave primaria: actor_id.
Configura una entrada para el resto de los nodos: Película, Categoría e Idioma.
Pestaña Relaciones (Relationships)
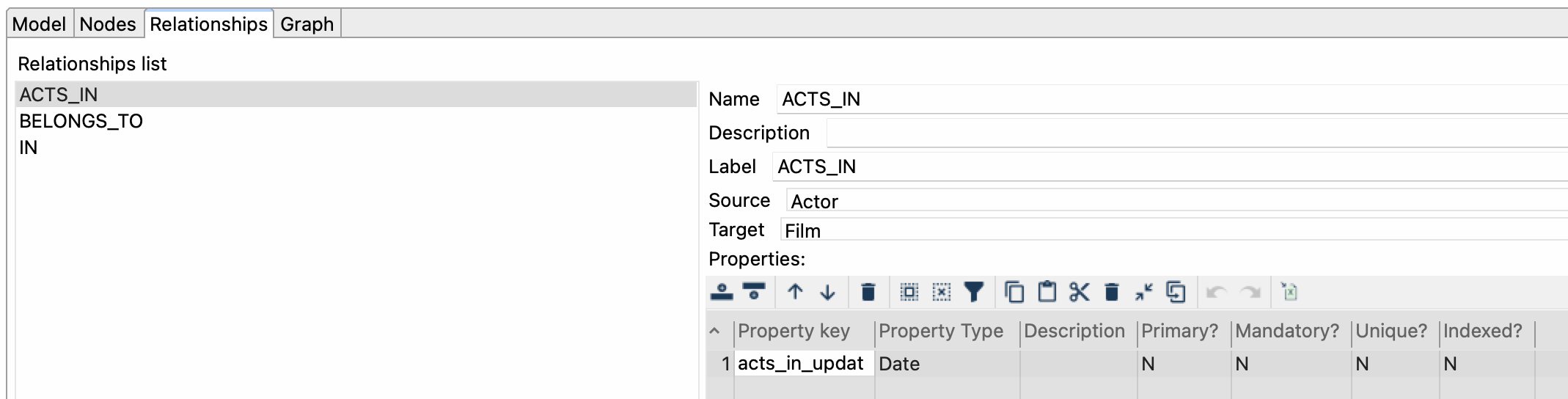
- Configura todas las relaciones especificando los campos:
- Nombre (Name): ACTS_IN
- Etiqueta (Label): ACTS_IN
- Origen (Source): Actor, especifica el nodo de origen de la relación.
- Destino (Target): Película, especifica el nodo de destino de la relación.
Pestaña Grafo (Graph)

Puedes verificar visualmente el modelo que creaste.
Este objeto de metadatos se puede utilizar en transformaciones o acciones dentro de Apache Hop para interactuar con la base de datos de grafo Neo4j. Por ejemplo, la transformación de Salida de Grafo en Apache Hop te permite mapear automáticamente campos de entrada a un modelo de grafo utilizando un objeto de metadatos de Modelo de Grafo Neo4j.
MongoDB Connection
El objeto de metadatos de Conexión de MongoDB en Apache Hop se utiliza para definir y configurar una conexión a una base de datos MongoDB. Al igual que otras conexiones de base de datos, este objeto de metadatos contiene diversas configuraciones para la conexión, como el nombre del host, el puerto, el nombre de usuario, la contraseña y la base de datos de autenticación. Además, permite al usuario especificar la base de datos y la colección que se consultarán o en las que se escribirán datos en la base de datos MongoDB.
Los usuarios también pueden definir la preferencia de lectura y las configuraciones de preocupación de escritura para la conexión, lo que determina el comportamiento de la base de datos en términos de consistencia y disponibilidad de datos.
Los principales campos a configurar son:

- Nombre de la conexión MongoDB (MongoDB Connection name): El nombre del objeto de metadatos.
- Nombre del servidor (Hostname): El nombre del host.
- Puerto (Port): El número de puerto.
- Nombre de la base de datos (Database name): El nombre de la base de datos MongoDB.
Una vez que se ha creado el objeto de metadatos de Conexión de MongoDB, se puede utilizar en las transformaciones de Apache Hop para leer o escribir datos en la base de datos de MongoDB conectada. Las transformaciones de Entrada de MongoDB y Salida de MongoDB permiten a los usuarios especificar el objeto de metadatos de Conexión de MongoDB, así como la consulta o el mapeo de campos que se ejecutará en la base de datos. Los usuarios también pueden especificar mapeos de campos de entrada y salida para definir cómo se leen o escriben los datos en la base de datos.
También es posible utilizar la transformación de Eliminación de MongoDB para ejecutar mapeos de eliminación en la base de datos.
Cassandra Connection
El objeto de metadatos Conexión de Cassandra de Apache Hop permite a los usuarios conectarse a una base de datos Cassandra para extraer y cargar datos. Con esta conexión, los usuarios pueden definir el host, el puerto, el keyspace y otras opciones de configuración para establecer una conexión con la base de datos Cassandra.
Al definir una conexión de Cassandra, los usuarios deben asegurarse de que tienen las credenciales y permisos necesarios para acceder a la base de datos. También es importante elegir opciones adecuadas para niveles de consistencia, compresión y otras configuraciones relacionadas con el rendimiento para garantizar una extracción y carga eficientes de datos.
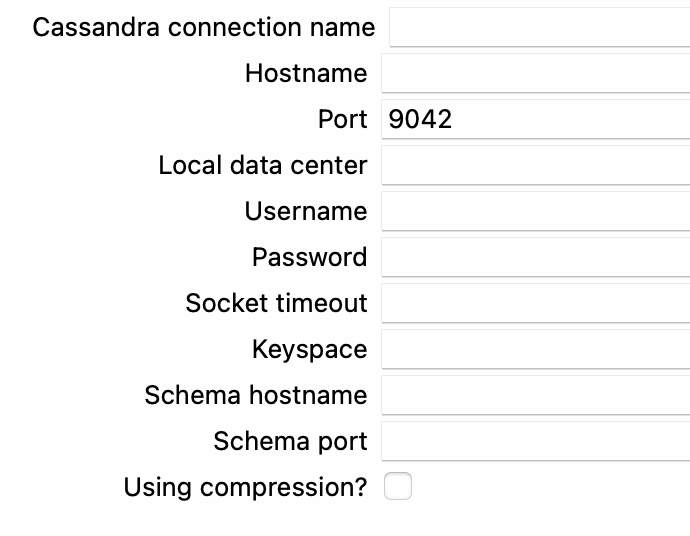
- Nombre del servidor (Hostname): Ingresa el nombre del servidor (o servidores) para conectarte al servidor de Cassandra.
- Puerto (Port): Especifica el número de puerto para la conexión al servidor de Cassandra.
- Nombre de usuario (Username): Ingresa el nombre de usuario de autenticación para el espacio de claves y/o tabla de destino.
- Contraseña (Password): Especifica la contraseña de autenticación para el espacio de claves y/o tabla de destino.
- Tiempo de espera de socket (Socket Timeout): Establece un período de tiempo de espera para la conexión, en milisegundos.
- Espacio de claves (Keyspace): Establece el nombre de la base de datos (espacio de claves). Utiliza el botón Seleccionar Espacio de Claves para elegir un espacio de claves o el botón Ejecutar CQL para crear uno.
- Nombre del servidor de esquema (Schema hostname): Para escrituras, ingresa el nombre del servidor de esquema (deja en blanco si es el mismo que el nombre del servidor).
- Puerto de esquema (Schema port): Para escrituras, ingresa el puerto de esquema (deja en blanco si es el mismo que el puerto).
- Usar compresión (Use compression): Selecciona esta opción para comprimir (con GZIP) el texto de cada sentencia INSERT BATCH antes de transmitirla al nodo.
Una vez que la conexión a Cassandra está definida, se puede utilizar en una variedad de transformaciones, como la Entrada de Cassandra, la Salida de Cassandra y la Consulta de Cassandra. La transformación de Entrada de Cassandra se utiliza para extraer datos de una tabla de Cassandra, mientras que la transformación de Salida de Cassandra se utiliza para cargar datos en una tabla de Cassandra. La transformación de Consulta de Cassandra se utiliza para ejecutar consultas personalizadas en la base de datos de Cassandra.
Splunk Connection
El objeto de metadatos "Conexión de Splunk" en Apache Hop se utiliza para definir las propiedades de conexión para acceder a los datos de Splunk. Este objeto de metadatos permite a los usuarios configurar una conexión a una instancia de Splunk especificando el host, el puerto y las credenciales necesarias para la autenticación.
Al crear un objeto de metadatos de conexión de Splunk, los usuarios pueden especificar el nombre de la conexión, una descripción y las propiedades de conexión. Las propiedades de conexión incluyen el nombre del host, el número de puerto, el esquema y las credenciales de autenticación. Los usuarios también pueden optar por utilizar un servidor proxy y establecer un valor de tiempo de espera para la conexión.

-
Nombre de la conexión (Connection name): Especifica un nombre para la conexión. Normalmente se utiliza para identificar una conexión específica cuando se utilizan múltiples conexiones.
-
Nombre del host o dirección IP (Hostname or IP address): Especifica el nombre o la dirección IP del servidor al que se realizará la conexión.
-
Puerto (Port): Especifica el número de puerto en el que el servidor está escuchando las conexiones.
-
Nombre de usuario (Username): Especifica el nombre de usuario para la conexión.
-
Contraseña (Password): Establece la contraseña para la conexión.
Una vez que se ha definido el objeto de metadatos de conexión de Splunk, los usuarios pueden utilizarlo en los diseños de (pipeline) canalización y (workflows) flujos de trabajo de Apache Hop para extraer datos de Splunk.
Partition Schema
En Apache Hop, un objeto de metadatos de esquema de partición representa la estructura de un conjunto de datos particionado. Este esquema especifica las claves utilizadas para la partición, el tipo de partición y cualquier opción adicional de partición. Es un componente crucial para definir un conjunto de datos que puede procesarse eficientemente en paralelo por sistemas distribuidos.
El esquema de partición en Apache Hop ofrece varias opciones de partición, incluyendo la partición hash, la partición de rango y la partición de lista. La partición hash distribuye los datos de manera uniforme entre las particiones mediante la creación de un valor de clave de hash, mientras que la partición de rango divide los datos según un rango específico de valores clave. La partición de lista, por otro lado, divide los datos según una lista específica de valores clave.
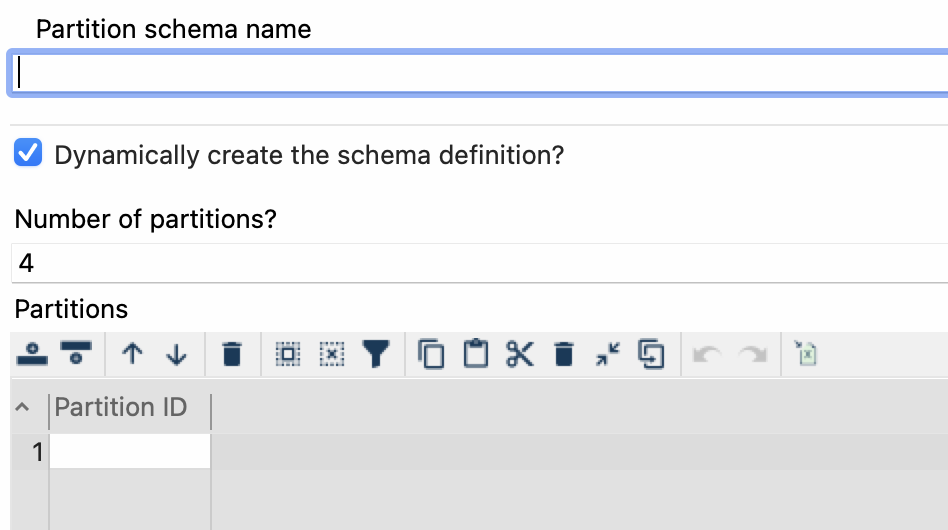
- ¿Crear dinámicamente la definición del esquema? (Dynamically create the schema definition?): Seleccione esta casilla de verificación para crear dinámicamente la definición del esquema.
- Número de particiones (Number of partitions): Este campo especifica el número de particiones que se utilizarán para almacenar los datos.
- Particiones (Partitions): Este campo especifica las particiones que se utilizarán para almacenar los datos. Cada partición se identifica mediante un identificador único y contiene un subconjunto de los datos.
Al utilizar un esquema de partición de objetos de metadatos, se puede lograr un procesamiento de datos más eficiente y escalable. Además, puede ayudar a optimizar la recuperación y procesamiento de datos al permitir consultas más específicas en conjuntos de datos grandes. Puedes revisar las pruebas de integración de Apache Hop a continuación para ver algunos casos de uso de muestra:
-
integration-tests/partitioning/0006-partitioned-when-stream-lookup-should-fail2.hpl
-
integration-tests/partitioning/0004-copies-repartitioning.hpl
-
integration-tests/partitioning/0001-static-partitioning.hpl
-
integration-tests/partitioning/0005-partitioned-stream-lookup.hpl
-
integration-tests/partitioning/0006-partitioned-when-stream-lookup-should-fail.hpl
-
integration-tests/partitioning/0003-repartitioning.hpl
-
integration-tests/partitioning/0005-non-partitioned-stream-lookup.hpl
-
integration-tests/partitioning/0002-dynamic-partitioning.hpl
Hop Server
En Apache Hop, el Servidor Hop es un objeto de metadatos que te permite ejecutar (pipelines) canalizaciones y (workflows) flujos de trabajo de forma remota. Esto te permite centralizar la gestión y ejecución de tus procesos de integración de datos en un solo servidor que puede ser accedido por varios usuarios o aplicaciones. El objeto de metadatos del Servidor Hop define las propiedades necesarias para conectarse a una instancia de Servidor Hop, como el nombre de host, número de puerto, nombre de usuario y contraseña.

- Nombre del servidor (Server name): el nombre que se utilizará para esta definición de servidor.
Pestaña Servicio (Service)
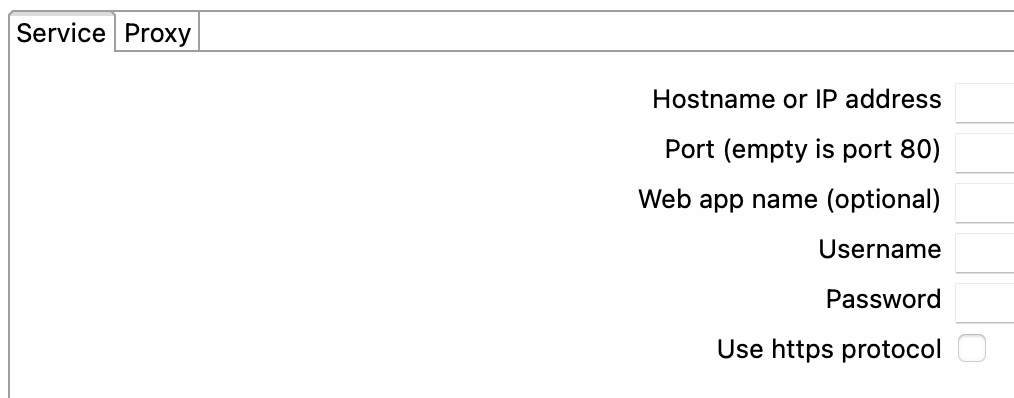
- Nombre de host o dirección IP (Hostname or IP address): el nombre de host o la dirección IP donde se ejecuta el servidor Hop.
- Puerto (Port, empty is port 80): el número de puerto a utilizar para el servidor Hop. Si está vacío, se establece en el puerto 80 de forma predeterminada.
- Nombre de la aplicación web (Web app name, optional): el nombre de la aplicación web a utilizar para el servidor Hop. Este campo es opcional.
- Nombre de usuario (Username): el nombre de usuario a utilizar para la autenticación al acceder al servidor Hop.
- Contraseña (Password): la contraseña a utilizar para la autenticación al acceder al servidor Hop.
- Usar el protocolo https (Use https protocol): una bandera booleana que indica si se debe utilizar el protocolo https para la comunicación con el servidor Hop. Si se establece en verdadero, se utiliza https; si se establece en falso, se utiliza http.
- Pestaña Proxy
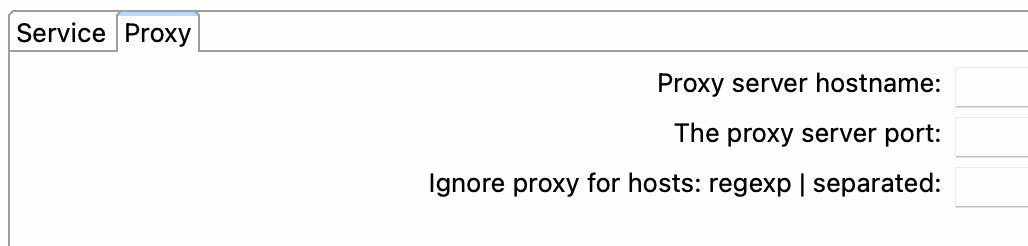
- Nombre del servidor proxy (Proxy server hostname): El servidor proxy.
- Puerto del servidor proxy (Proxy server port): Especifique el puerto del servidor proxy.
- Ignorar el proxy para hosts (Ignore proxy for hosts): regexp|separados: Permite al usuario especificar una expresión regular o una lista separada de hosts que no deben utilizar el servidor proxy configurado para la comunicación. Por ejemplo, si la expresión regular se establece en "localhost|127.0.0.1" o la lista separada se establece en "localhost,127.0.0.1", entonces el Hop Server evitará el servidor proxy al comunicarse con hosts que coincidan con "localhost" o "127.0.0.1".
Una vez que el servidor Hop está definido, se puede utilizar para facilitar la ejecución de (workflows) flujos de trabajo y (pipelines) canalizaciones de forma remota mediante el uso de las (Pipeline Run Configuration) Configuración de Ejecución de Canalizaciones remotas o (Workflow Run Configuration) Configuración de Ejecución de Flujos de Trabajo remotos. Para ejecutar Hop Server, puedes utilizar el script disponible en el directorio de instalación de Hop. En Windows, el script se llama "hop-server.bat", mientras que en Mac y Linux, se llama "hop-server.sh". Si ejecutas el script sin ningún parámetro, mostrará las opciones de uso para Hop Server. Hop Server se puede utilizar en conjunto con los tipos de metadatos de Servicio Web y Servicio Web Asíncrono. Consulta la Documentación Oficial de Hop para obtener más detalles.
Relación entre Hop Server y la (Pipeline Run Configuration) Configuración de Ejecución de Canalizaciones y (Workflow Run Configuration) Configuración de Ejecución de Flujos de Trabajo: En Apache Hop, el servidor Hop es el componente que permite la ejecución remota de canalizaciones y flujos de trabajo. En la primera publicación sobre este tema, cubrimos los objetos de metadatos de (Pipeline Run Configuration) Configuración de Ejecución de Canalizaciones y (Workflow Run Configuration) Configuración de Ejecución de Flujos de Trabajo. Estos objetos permiten a los usuarios especificar y almacenar configuraciones de tiempo de ejecución para canalizaciones y flujos de trabajo. Uno de los posibles tipos de motor es el motor remoto de Hop. Al especificar este motor, el usuario puede seleccionar un objeto de metadatos de servidor Hop para la ejecución.
Web Service
El objeto de metadatos de Servicio Web en Apache Hop se utiliza para ejecutar canalizaciones en un servidor Hop. Permite a un usuario ejecutar una canalización como un servicio. El usuario puede definir el nombre del servicio, el nombre de archivo en el servidor donde se encuentra la canalización, la transformación de la cual el servicio tomará las filas de salida, etc. Además, el usuario puede habilitar la opción para listar las ejecuciones de la canalización de servicio web en el estado del servidor y especificar el nombre de la variable que contendrá el contenido del cuerpo de la solicitud en tiempo de ejecución.
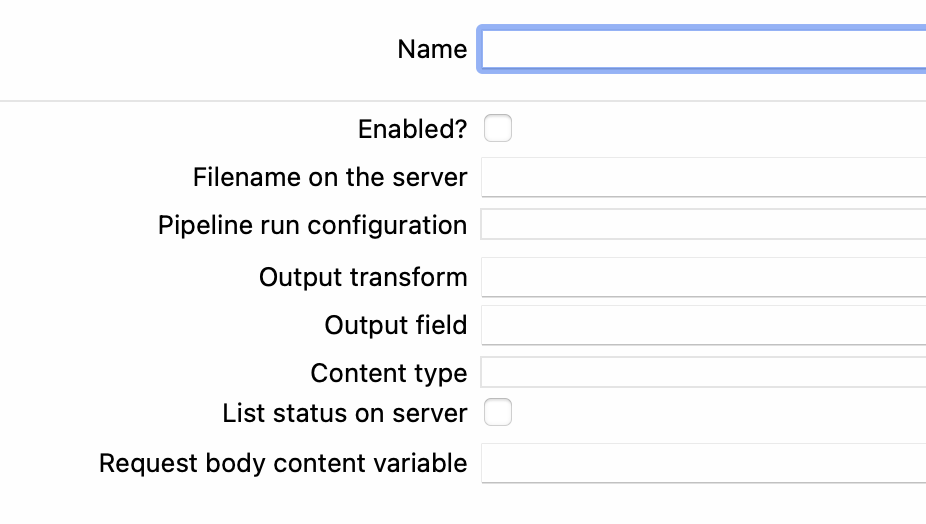
-
Nombre del servicio web (Web service name): Este campo especifica el nombre del servicio web que se utilizará en la URL del servicio web para acceder al servicio.
-
Habilitado (Enabled): Este campo se utiliza para habilitar o deshabilitar el servicio web.
-
Nombre del archivo en el servidor (Filename on the server): Este campo especifica el nombre del archivo de la canalización que debe ejecutarse en el servidor Hop. El archivo debe estar disponible en el servidor para una ejecución exitosa.
-
Configuración de ejecución de la canalización (Pipeline Run Configuration): La configuración de ejecución de la canalización que se utilizará para las ejecuciones.
-
Transformación de salida (Output transform): Este campo especifica el nombre de la transformación de la cual el servicio web tomará la(s) fila(s) de salida.
-
Campo de salida (Output field): Este campo especifica el campo de salida del cual el servicio web tomará los datos, los convertirá en una cadena y los emitirá.
-
Tipo de contenido (Content type): Este campo especifica el tipo de contenido que informará el servlet del servicio web.

-
Listar estados en el servidor (List status on server): Este campo habilita la lista de ejecuciones de canalizaciones de servicio web en el estado del servidor Hop.
-
Variable de contenido del cuerpo de la solicitud (Request body content variable): Este campo especifica el nombre de la variable que contendrá el contenido del cuerpo de la solicitud en tiempo de ejecución. Es útil al realizar una solicitud POST al servicio web.
Para garantizar que un servidor Hop tenga acceso a los metadatos que has definido, debes asegurarte de que el servidor pueda acceder tanto a las canalizaciones que deseas ejecutar como a los metadatos del servidor. La forma recomendada de lograrlo es configurando la siguiente opción en tu archivo de configuración XML:
<metadata_folder>/path/to/your/metadata</metadata_folder>Un ejemplo:
<hop-server-config> <hop-server> <name>8181</name> <hostname>localhost</hostname> <port>8181</port> </hop-server> <metadata_folder>/home/hop/project/services/metadata</metadata_folder> </hop-server-config>La solicitud base es la siguiente, pero puedes especificar parámetros.
http://<hop-server-url>/hop/webServiceChequea Hop Official Documentation para más detalles.
Relación entre Hop Server y Web Service
En Apache Hop, el Hop Server es el servidor ligero utilizado para ejecutar flujos de trabajo y pipelines de forma remota. El tipo de metadatos Web Service se utiliza para definir un servicio web que puede ser accedido de forma remota a través del Hop Server. Una vez que el Web Service está definido, puede ser accedido de forma remota a través del Hop Server.
Asynchronous Web Service
Este tipo particular de servicio web está diseñado para ejecutar flujos de trabajo que requieren mucho tiempo para completarse. A diferencia de otros servicios web que proporcionan resultados inmediatos después de llamar a un flujo de trabajo, este servicio solo devuelve un ID único que representa el flujo de trabajo en ejecución. Este ID puede ser utilizado para verificar el estado del flujo de trabajo. Además, es posible especificar variables adicionales que se informarán al consultar el estado del flujo de trabajo asíncrono.

- Nombre (Name): El nombre del Servicio Web Asíncrono. Este es el nombre que se pasa en la URL del "asyncRun" del Servicio Web. Ejemplo: "http://localhost:8282/hop/asyncRun/?service=runmainworkflow".
- Habilitado (Enabled): Un indicador booleano que indica si el servicio web está habilitado o no.
- Nombre de archivo (Filename): El nombre del flujo de trabajo que se utilizará para este servicio web. Puedes optar por abrir un flujo de trabajo existente, crear uno nuevo o buscar y seleccionar un flujo de trabajo existente.
- Variables de estado (Status variables): Una lista de variables que se informarán cuando se consulte el servicio de estado asíncrono. Estas variables están separadas por comas.
- ariable de contenido (Content variable): El nombre de la variable que contendrá el cuerpo del contenido de la llamada de servicio.
Relación entre el Servidor Hop y el Servicio Web
En Apache Hop, los objetos de metadatos del Hop Server y el Servicio Web Asíncrono están relacionados en el sentido de que la variante del Servicio Web Asíncrono se utiliza para ejecutar flujos de trabajo de larga duración en el Hop Server. Cuando se utiliza el objeto de metadatos del Servicio Web Asíncrono, en lugar de obtener resultados inmediatos de un flujo de trabajo con una llamada al Servicio Web, lo único que se devuelve después de la llamada es el ID único del flujo de trabajo en ejecución.
Este ID único se puede utilizar para consultar el estado del flujo de trabajo, incluyendo cualquier variable adicional que se haya especificado para ser informada durante la consulta del estado del flujo de trabajo en ejecución de forma asíncrona. El Hop Server se puede acceder en combinación con ambos tipos de metadatos del Servicio Web y del Servicio Web Asíncrono para ejecutar flujos de trabajo y canalizaciones de forma remota.
Ventajas del Uso de Metadatos en Apache HopEl uso de objetos de metadatos en Apache Hop para procesos de integración de datos tiene varios beneficios:
-
Reutilización: Los objetos de metadatos se pueden reutilizar en múltiples (workflows) flujos de trabajo y (pipelines) canalizaciones, lo que reduce la cantidad de tiempo y esfuerzo necesarios para crear nuevos procesos de integración de datos.
-
Consistencia: Al definir objetos de metadatos como conexiones de base de datos, formatos de archivo y definiciones de esquema, se garantiza la consistencia en los (workflows) flujos de trabajo y las (pipelines) canalizaciones, lo que reduce el riesgo de errores y mejora la calidad de los datos.
-
Gestionabilidad: Los objetos de metadatos se pueden gestionar de forma centralizada, lo que facilita su actualización y mantenimiento en múltiples (workflows) flujos de trabajo y (pipelines) canalizaciones.
-
Flexibilidad: Con objetos de metadatos, es posible cambiar fácilmente entre diferentes fuentes y destinos de datos sin tener que actualizar todo el (workflow) flujo de trabajo o la (pipeline) canalización.
-
Colaboración: Los objetos de metadatos se pueden compartir entre miembros del equipo, lo que mejora la colaboración y reduce el riesgo de errores o malentendidos.
Los objetos de metadatos simplifican y estandarizan el procesamiento de datos en (workflows) flujos de trabajo y (pipelines) canalizaciones al proporcionar una forma centralizada de gestionar elementos comunes de integración de datos, como conexiones de base de datos, formatos de archivo y definiciones de esquema. En lugar de tener que configurar manualmente cada uno de estos elementos para cada (workflow) flujo de trabajo o (pipeline) canalización, los objetos de metadatos se pueden definir una vez y reutilizar en múltiples procesos.
Este enfoque garantiza la consistencia en los procesos de integración de datos, lo que reduce el riesgo de errores y mejora la calidad de los datos. Además, los objetos de metadatos se pueden actualizar y mantener fácilmente, lo que facilita la gestión de cambios en las fuentes de datos, destinos o lógica de procesamiento.
Al proporcionar una forma estándar de definir y gestionar objetos de metadatos, Apache Hop simplifica el desarrollo y la implementación de procesos de integración de datos. Este enfoque facilita la colaboración en proyectos de integración de datos y garantiza que el procesamiento sea consistente, repetible y confiable en diferentes entornos y casos de uso.
Mejores Prácticas para Utilizar Metadatos en Apache Hop
Aquí tienes algunas mejores prácticas para utilizar objetos de metadatos en Apache Hop:
-
Utiliza convenciones de nombres claras y consistentes para los objetos de metadatos para que sean fáciles de identificar y utilizar en (workflows) flujos de trabajo y pipelines. Por ejemplo, utiliza nombres que reflejen el propósito del objeto de metadatos y el tipo de datos que representa.
-
Usa variables definidas en el archivo de configuración del entorno para definir los objetos de metadatos. Este enfoque proporciona una forma más dinámica y flexible de gestionar los objetos de metadatos, ya que te permite actualizar fácilmente los valores de las variables sin necesidad de modificar los propios objetos de metadatos.
-
Emplea la herencia de metadatos para evitar la duplicación de información en varios objetos. Por ejemplo, puedes crear un objeto de metadatos para una conexión de base de datos que se utiliza en varios proyectos y luego crear un proyecto principal que se utiliza como padre para otros proyectos que heredan los detalles de la conexión.
-
Utiliza la inyección de metadatos para poblar objetos de metadatos de forma dinámica en tiempo de ejecución. Esto puede ser especialmente útil cuando necesitas procesar datos de múltiples fuentes que tienen propiedades de metadatos diferentes.
-
Utiliza el control de versiones para gestionar los cambios en tus objetos de metadatos con el tiempo. Esto puede ayudarte a realizar un seguimiento de los cambios y volver a versiones anteriores si es necesario.
-
Documenta tus objetos de metadatos para que sea más fácil para otros usuarios comprender su propósito y utilizarlos eficazmente. Esto puede incluir información sobre la fuente de datos, tipos de datos y otros detalles relevantes.
Siguiendo estas mejores prácticas, puedes utilizar objetos de metadatos en Apache Hop para optimizar tus procesos de integración de datos, haciéndolos más eficientes y fáciles de gestionar con el tiempo.
Conclusiones
Este artículo ofrece una descripción general de los objetos de metadatos en Apache Hop, una herramienta de integración de datos de código abierto. El artículo explica la importancia de los objetos de metadatos y sus diferentes tipos, incluyendo 10 de los 20 tipos de metadatos en Apache Hop. Los beneficios de utilizar objetos de metadatos incluyen la reutilización, la consistencia, la facilidad de gestión y la flexibilidad. El artículo también proporciona mejores prácticas para crear y gestionar objetos de metadatos en Apache Hop.
En Apache Hop, los objetos de metadatos se utilizan para definir las entradas y salidas de los (workflows) flujos de trabajo, el formato y la estructura de las fuentes y destinos de datos, y la configuración de varios componentes de Hop. Se almacenan en un repositorio de metadatos centralizado, lo que permite un fácil acceso y gestión de los objetos de metadatos en múltiples proyectos.
Los objetos de metadatos también permiten la automatización de los procesos de integración de datos al proporcionar una forma de manipular y configurar de manera programática los (workflows) flujos de trabajo y las (pipelines) canalizaciones. Al definir los objetos de metadatos una vez, se pueden reutilizar en múltiples (workflows) flujos de trabajo y (pipelines) canalizaciones, lo que ahorra tiempo y esfuerzo en el desarrollo y el mantenimiento.

