Esta publicación se basa en el contenido cubierto en la publicación anterior (Ejecución de Pipelines en Apache Hop: Distribución y Copia), donde presentamos los principios de la ejecución de pipelines y los dos principales movimientos de datos: distribución y copia.
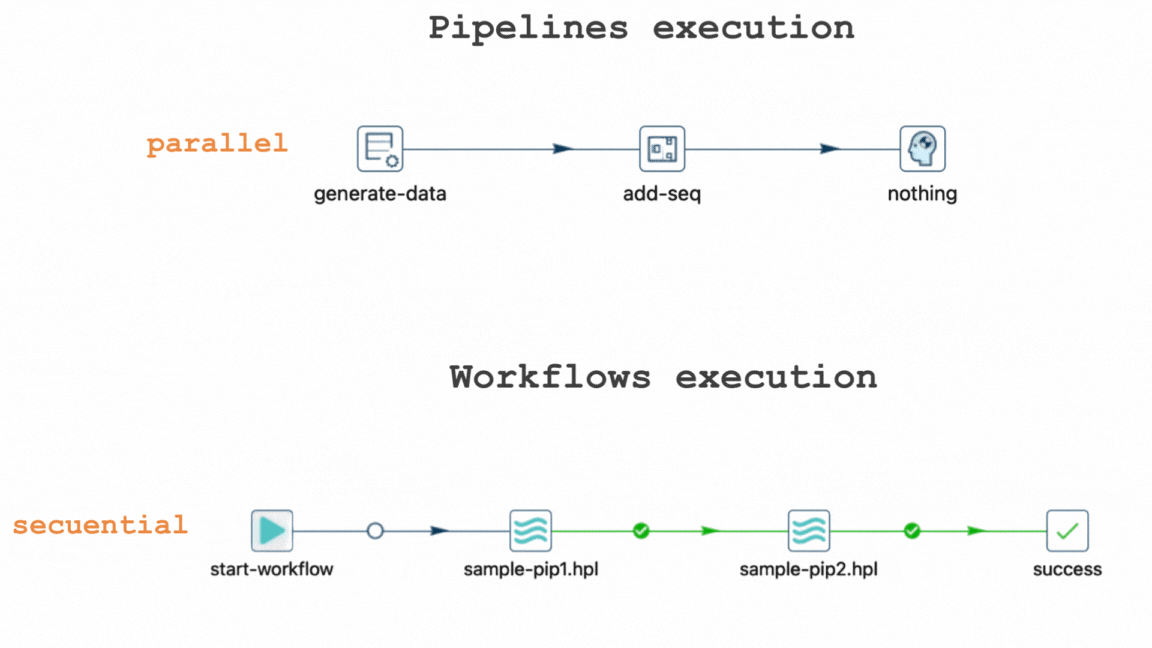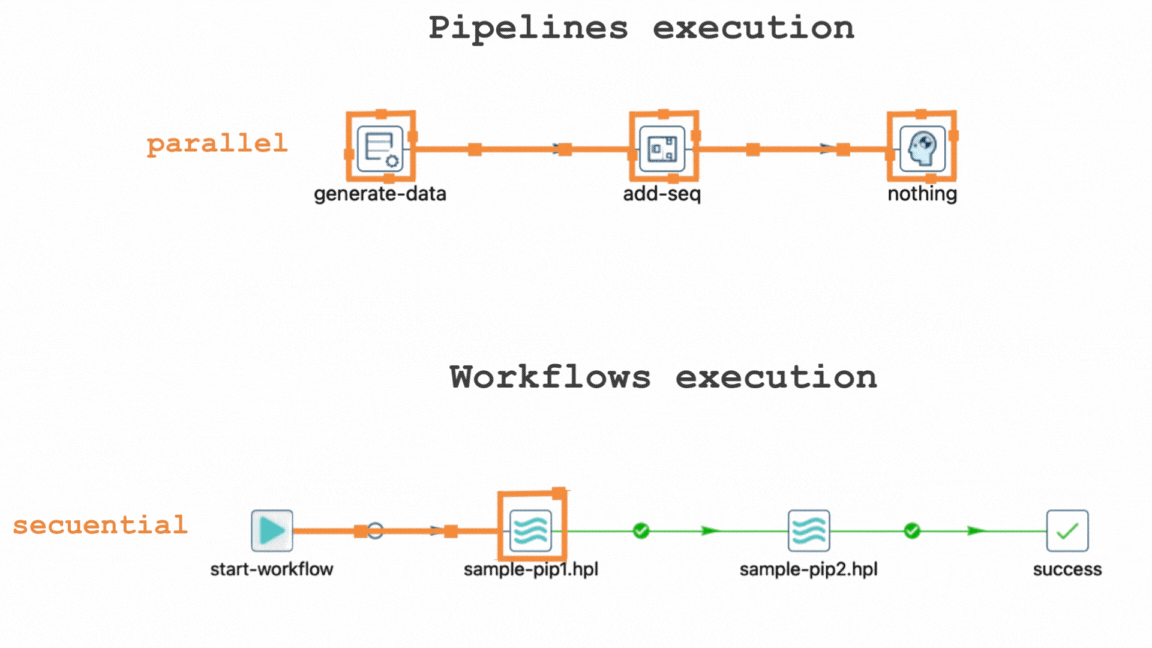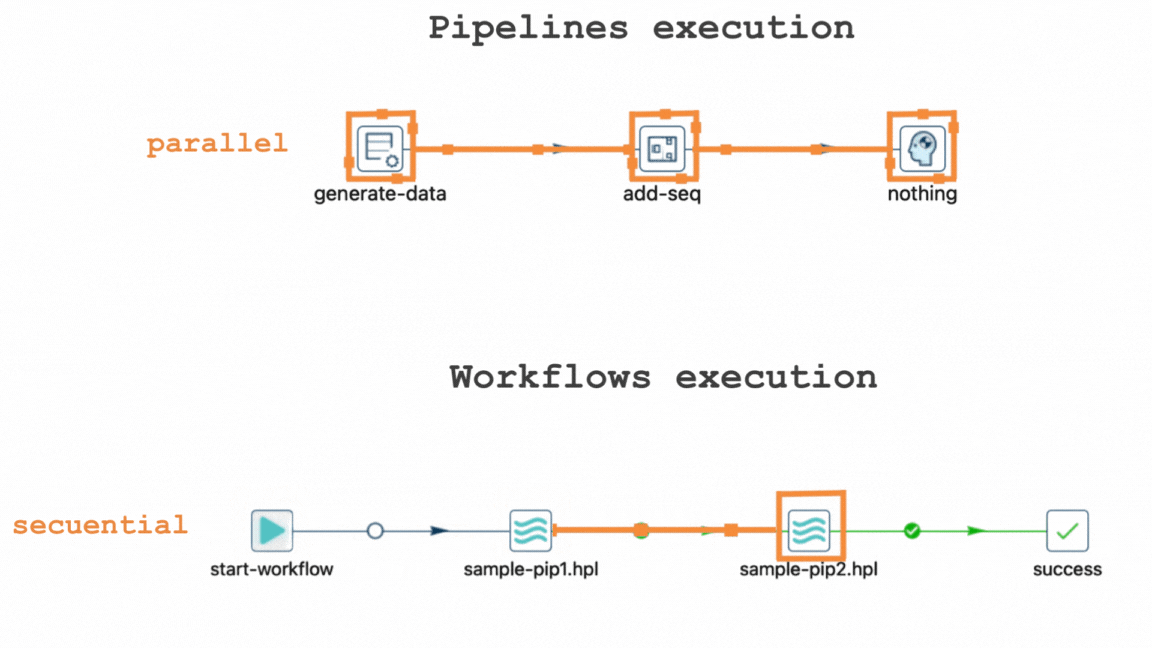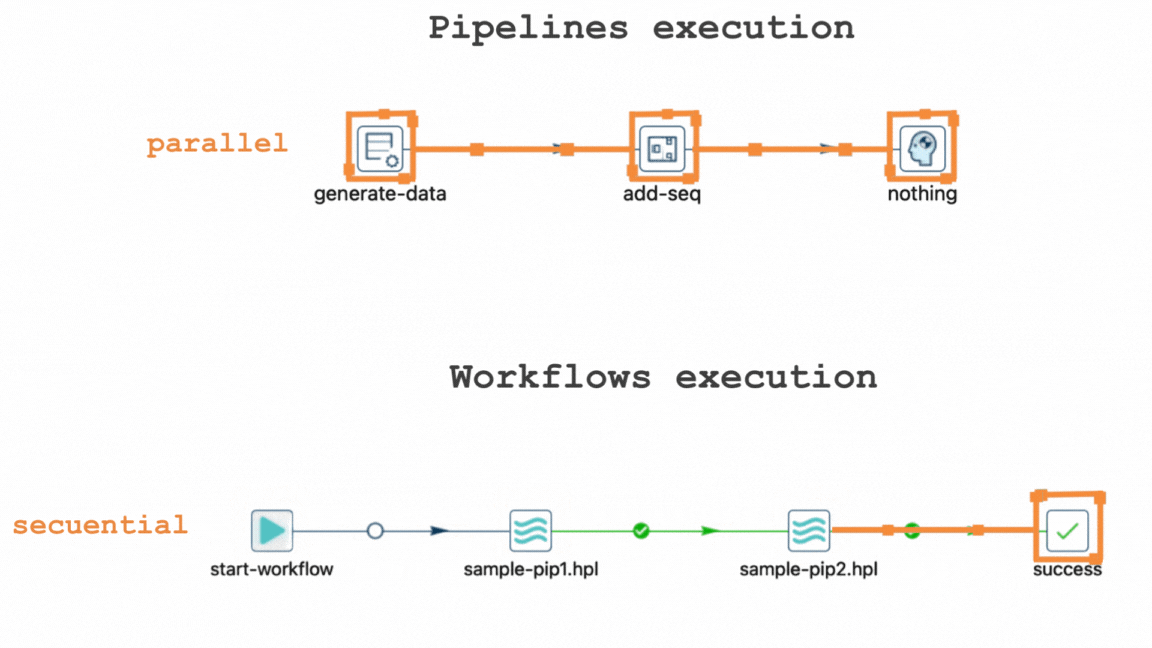
#2 El método de movimiento de datos por defecto es la distribución. El método de distribución envía filas por turnos.
#3 Seleccionar explícitamente la opción de copia asegura que todas las transformaciones conectadas reciban todas las filas.

Esta vez, profundicemos en algunos consejos esenciales sobre la ejecución de pipelines y movimientos de datos.
Nuestro nuevo plan implica explorar escenarios donde los resultados de la ejecución dependen de la implementación específica o de las transformaciones utilizadas.
Empecemos con el primer ejemplo.
En nuestra publicación anterior, discutimos las opciones de distribuir o copiar datos al conectar una transformación a otras dos.
Sin embargo, ¿qué ocurre al usar una transformación de filtro?
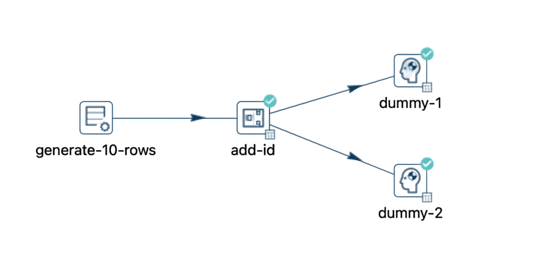
En este ejemplo, hemos introducido una condición para filtrar valores mayores a 5 en la secuencia de datos.
Ahora, observa que al conectar el filtro a la primera transformación, se muestran diferentes opciones.
En este escenario, puedes seleccionar una transformación para recibir las filas que cumplen con las condiciones, mientras que la otra transformación recibirá las filas que no las cumplen.
Seleccionamos "dummy-1" para verdadero y "dummy-2" para falso.
Cuando ejecutas este pipeline, la operación de filtro resulta en una distribución, pero no es una distribución aleatoria. Los resultados verdaderos se dirigen a "dummy-1", mientras que los resultados falsos se envían a "dummy-2".
Hasta ahora, hemos visto escenarios con una sola transformación conectando a dos transformaciones subsiguientes: distribución, copia y distribución a través de filtrado.
Pero, ¿qué pasa si necesitas realizar operaciones como unir o anexar secuencias de datos?
En el escenario simplificado proporcionado, dos pequeñas secuencias de datos se ordenan y posteriormente se unen utilizando una transformación de "Merge join".
Se realiza una unión interna con los datos provenientes de "sort-id" y "sort-id-2" utilizando el campo id.
Es crucial notar que los datos deben estar ordenados antes de realizar la unión.
Al pasar el cursor sobre el ícono de información azul visible, se muestra este mensaje.
El mensaje indica que las filas se envían a la transformación "merge-rows" para servir como información adicional.
Además, menciona que la transformación de destino "sort-id-2" se trata como un caso especial y que las reglas estándar de lectura no se aplican en este caso.
Pero, ¿cómo funciona esto en la práctica?
En este escenario, la transformación "Merge join" no procesa ninguna fila hasta que hayan sido procesadas por las transformaciones "Sort rows".
Utiliza los datos ordenados de "sort-id" como referencia y realiza la unión con los datos ordenados de "sort-id-2".
Durante la ejecución, usando un ejemplo similar con 5 000 000 de filas en cada secuencia de datos, se ve así.
Nota que la transformación “merge-rows” no inicia su ejecución hasta que todas las filas están ordenadas, momento en el cual comienza a ejecutar la unión y gradualmente envía las filas a la transformación ”Dummy”.
Ahora, examinemos un tercer y último ejemplo.
Considera un escenario donde concatenas dos secuencias de datos en una sola.
En tal caso, todos los pipelines comienzan simultáneamente y si ordenas los datos antes de anexarlos, la ejecución ocurre como en el ejemplo anterior, con la ejecución paralela continuando después de ordenar las filas.
Observaciones
#1 En esta publicación cubrimos algunos ejemplos de cómo se ejecuta un pipeline cuando los datos se filtran, unen o anexan. Ten en cuenta que las transformaciones utilizadas no son las únicas opciones en Apache Hop para realizar esas operaciones.
Por ejemplo, para filtrar datos también puedes usar las transformaciones "Java filter" o "Switch case".
Las transformaciones "Join rows", "Merge rows", "Database join", etc., para realizar uniones.
#2 La transformación "Filter Rows" te permite filtrar filas basadas en condiciones y comparaciones especificadas. Influye en el flujo de trabajo al vincular los resultados Verdadero o Falso a otras transformaciones. Hay tres rutas disponibles como salidas: Verdadero, Falso y Principal. La salida Principal sigue exclusivamente la ruta Verdadero.
#3 La transformación "Merge join" ejecuta una unión tradicional entre conjuntos de datos provenientes de dos transformaciones de entrada distintas. Esta transformación opera bajo la suposición de que tus datos están ordenados según las claves de unión. Las opciones de unión incluyen INNER, LEFT OUTER, RIGHT OUTER y FULL OUTER.
#4 Si te importa el orden en que ocurren las filas de salida, puedes usar la transformación "Append Streams". Si el orden de las filas de salida no es significativo, cualquier transformación puede ser utilizada para amalgamar dos o más secuencias de datos en una unión.