













Delve into Apache Hop's Pipeline Logging feature for efficient data processing. Uncover insights...
Discover Apache Hop's Workflow Logging feature for efficient data processing. Uncover insights and best practices in this guide.
Workflow Log
Apache Hop changes the way data and metadata are handled by establishing a distinct boundary between them. This separation empowers you to craft data processes autonomously from the actual data. Centralizing essential metadata like database connections, run configurations, servers, datasets, and beyond, the Apache Hop Metadata acts as a hub for shared metadata. An invaluable feature, the "Workflow Log," enables seamless logging of workflow activities in connection with pipelines.

The "Workflow Log" metadata object streams logging information from a running workflow to a pipeline and is created in JSON format. For each metadata object of this type, you can execute a pipeline of your choice, passing the runtime information of all your workflows to it.
"Workflow Log" Configuration
To configure and use the "Workflow Log" metadata, follow these steps:
Step 1: Create a "Workflow Log" Metadata Object
-
In the horizontal menu click on "New" -> "Workflow Log".
.png?width=533&height=400&name=Mi%20proyecto%20(1).png)
-
Or go to "Metadata" -> "Workflow Log." -> "New".

-
Fill in the required fields:

-
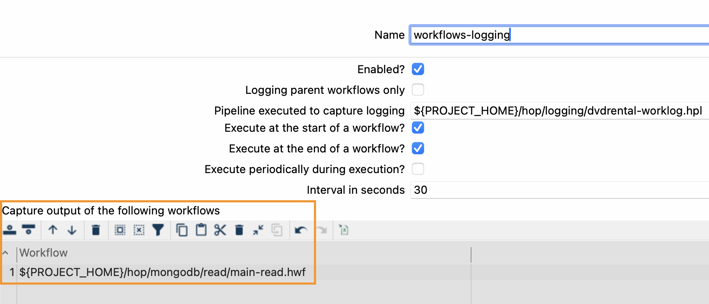
Name: Provide a name for the metadata object (workflows-logging).
-
Enabled: Check this option to activate the logging.
-
Logging parent workflows only: This option is unchecked in our provided example. It specifies whether the pipeline logging should capture and process logging information only for the parent workflows (the workflow being run), or if it should also capture and process logging information for sub-workflows that may be executed as part of the main parent workflow.
-
Pipeline executed to capture logging: Select or create the pipeline that processes the logging information for this "Workflow Log". Specify the directory of the pipeline (${PROJECT_HOME}/hop/logging/workflows-logging.hpl). We'll detail this in the second step.
-
Execute at the start of the workflow?: This option remains chosen in our provided example. The option specifies whether this workflow log should be executed at the start of a workflow run. If set to true, the logging will begin at the beginning of the workflow execution.
-
Execute at the end of the workflow?: We keep this selected in our example. It determines whether this workflow log should be executed at the end of a workflow run. If set to true, the logging will occur once the workflow has completed its execution.
-
Execute periodically during execution?: We leave this unchecked. Indicates whether this workflow log should be executed at regular intervals during a workflow run. If set to true, the log will be executed periodically.
-
Interval in seconds: Specifies the interval, in seconds, at which the workflow log is executed if "Execute periodically during execution" is set to true. The workflow log will be triggered at this specified interval during the workflow execution.
-
- Save the configuration.
Step 2: Create a New Pipeline with the "Workflow Logging" Transform
-
Create a new pipeline from the "New" option in the "Workflow Log" dialog by choosing a folder and a name.

-
The pipeline is automatically generated with a "Worflow Logging" transform connected to a "Dummy" transform ("Save logging here"). Now we'll configure another output for this pipeline. You can also create the pipeline from scratch.

-
Configure the "Workflow Logging" transform:

-
Transform name: Provide a unique name for the transform (worklog).
-
Also log action details: We keep this option checked.
- Checked: The transform generates both workflow and action logging and metrics. In this scenario, the log will have a line for each action, containing both workflow logging and metrics information.
- Unchecked: The transform exclusively produces workflow logging and metrics
-
Step 3: Add and Configure a "Table Output" Transform

-
Remove the "Dummy" transform.
-
Add a "Table Output" transform to load data into a database table:

-
Click anywhere on the pipeline canvas.
-
Search for 'table output' -> Table Output.
-
-
Configure the "Table Output" transform:

-
Transform name: Provide a unique name for the transform (workflows-logging).
-
Connection: Select the database connection where the data will be written (dvdrental-connection), which was configured using the logging-connection.json environment file.
-
Target schema: Specify the schema name for the table where data will be written. (logging).
-
Target table: Specify the table's name to which data will be written (worklog).
-
Click on the SQL option to automatically generate the SQL for creating the output table.

-
-
Execute the SQL statements and verify the logging fields in the created table.


-
Save and close the transform.
Step 4: Run a Workflow and Check the Logs
-
Launch a pipeline by clicking on "Run" -> "Launch."
-
We use a main workflow (main-read.hwf) that runs 3 pipelines. Each pipeline loads an entity in a MongoDB database. See the post Effortlessly Migrate Data to MongoDB with Apache Hop.

-
The workflow and each action execution data will be recorded in the worklog table. The execution of the pipelines included in the workflow will be recorded in the "piplog" table. See the preview post Understanding and Utilizing Pipeline Logging in Apache Hop.
-
Check the data in the "piplog" and the "worklog" table to review the logs.


Conclusion
Configuring the "Workflow Log" is a breeze, offering the choice to trigger at the workflow's start or finish (inclusive of pipelines and workflows executed within). Moreover, it allows periodic execution, providing tailored logging strategies aligned with project requirements. The flexibility to define the execution interval adds a further layer of customization.
To sum up, Apache Hop's "Workflow Log" stands as a pivotal instrument for efficient logging within data processing workflows. Its configurable nature and seamless integration into Apache Hop's ecosystem make it an invaluable asset for data engineers and developers aiming to elevate logging capabilities and maintain resilient data processes. With the distinct segregation of data and metadata and enriched by robust features like the "Workflow Log," Apache Hop solidifies its position as a frontrunner for streamlined and effective data integration and processing.

