{kind=link}
{kind=link}
.png){kind=link}
-1.png){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
<metadata_folder>/path/to/your/metadata</metadata_folder>The use of metadata objects in data integration processes has become increasingly important in recent years, and Apache Hop is no exception. With metadata objects, users can easily manage and maintain complex data pipelines and processing tasks by defining and standardizing data definitions, connection information, and processing rules across different workflows and pipelines.
In this two-part post, we will delve into the power of metadata objects in Apache Hop, covering the different types of objects available, their benefits, use cases, and step-by-step instructions for creating and managing them using the Hop graphical user interface (Hop GUI). In this second post, we will cover essential metadata objects, including Relational Database Connection, Neo4j Connection, Neo4j Graph Model, MongoDB Connection, and more.
By the end of this series, readers will have a comprehensive understanding of metadata objects in Apache Hop and best practices for using them effectively in data integration workflows.
Check the first post: The Power of Metadata Objects in Apache Hop: A Comprehensive Guide I
There are several ways to create and manage metadata objects using the Apache Hop graphical user interface Hop GUI. It depends on the metadata type but in this post, we'll cover two of them.
First way
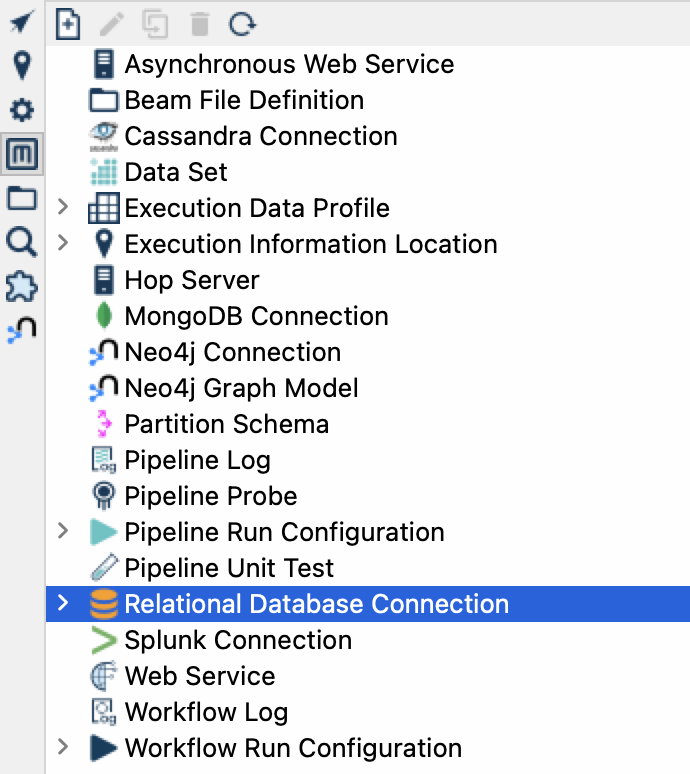
Open the Apache Hop GUI and select the Metadata perspective.
Select a Metadata object type and hit the New button.
Fill in the details for the metadata object, such as the connection details for a database or the file definition.
Click OK to save the metadata object.
Second way
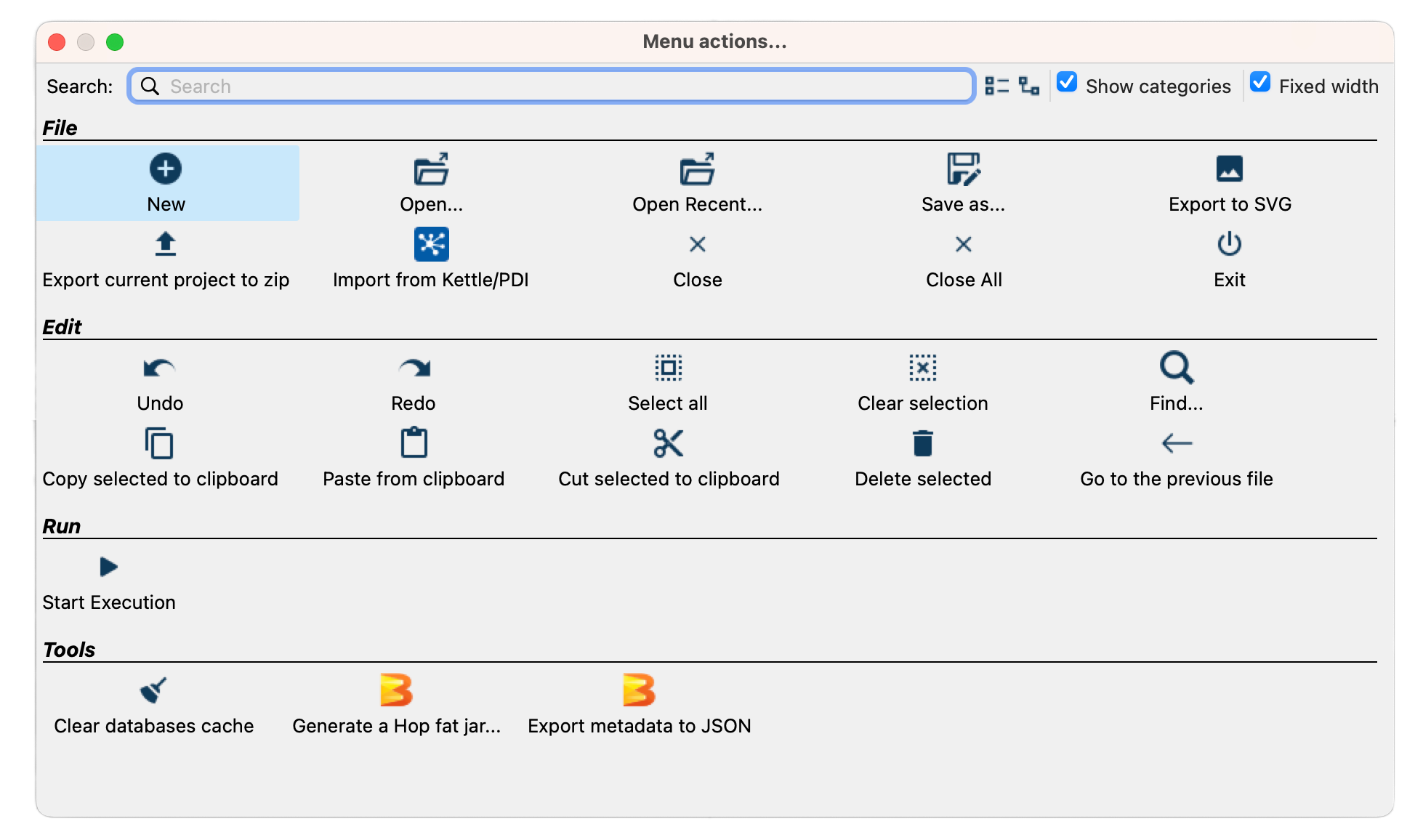
Open the Apache Hop GUI and hit the Hop->New or the New visible button in the Horizontal menu.
Select the type of metadata object you want to create from the context menu. This will send you to the Metadata perspective and the dialog with the fields to be filled in will be opened.
Fill in the details for the metadata object, such as the connection details for a database or the file definition.
Click OK to save the metadata object.
Once you have created a metadata object, you can use it in your workflows and pipelines by referencing it in the appropriate action/transform.
To manage metadata objects, you can use the Metadata perspective to view, edit, or delete existing objects.
Apache Hop provides a variety of metadata objects that users can create and manage to streamline the data integration process. Until now (Apache Hop 2.4), the types of metadata objects in Apache Hop are:
Yes, there are many metadata objects to cover, which is good news. There is no need to panic because we will guide you through each of them, provide examples, and clarify the dependencies between some of them. This is the second of two posts where we’ll cover all of the current metadata objects in Apache Hop. Check the first post The Power of Metadata Objects in Apache Hop: A Comprehensive Guide I.
This second post will include the following metadata objects:
The Relational Database Connection metadata object in Apache Hop is used to define connections to relational databases, such as MySQL, Oracle, PostgreSQL, SQL Server, and more. This metadata object provides a way to configure the parameters required to connect to a specific database, such as hostname, port, database name, username, and password.
When creating a new Relational Database Connection in Apache Hop, the user is prompted to enter the necessary information for the database they want to connect to, but it depends on the type of database. You may build a Generic connection or use one of the several database types offered by Apache Hop to make a database connection.
For instance, if you choose PostgreSQL as your connection type, the following fields will appear:
After the connection has been established, the user can easily reference it in other components, such as the Table Input or Table Output transforms, to read or write data from the specified database.
Using the Relational Database Connections metadata object allows for more efficient and standardized management of database connections in Apache Hop.
By defining a connection once and using it throughout a workflow, the user can avoid duplicating connection information and ensure consistency in how the connection is used across different components.
Additionally, the metadata object allows for easy updating of connection information if needed, without having to manually update each component that uses the connection.
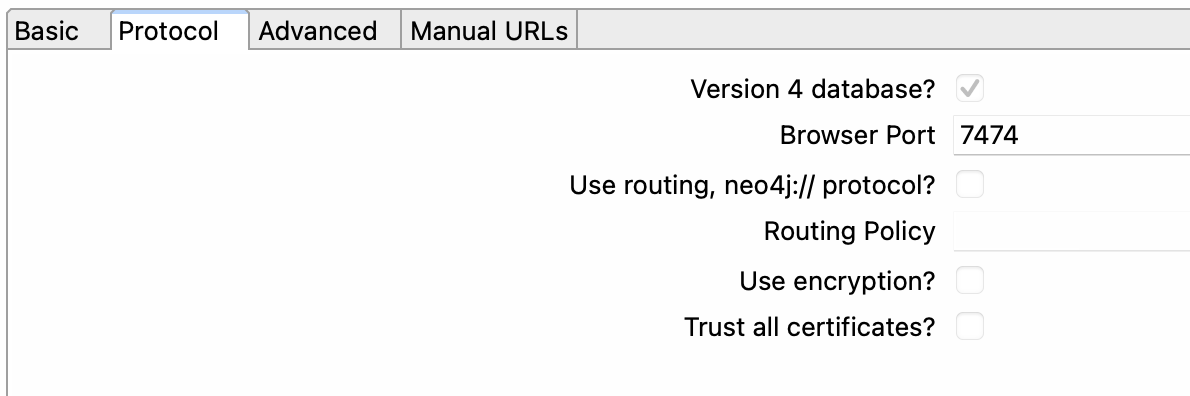
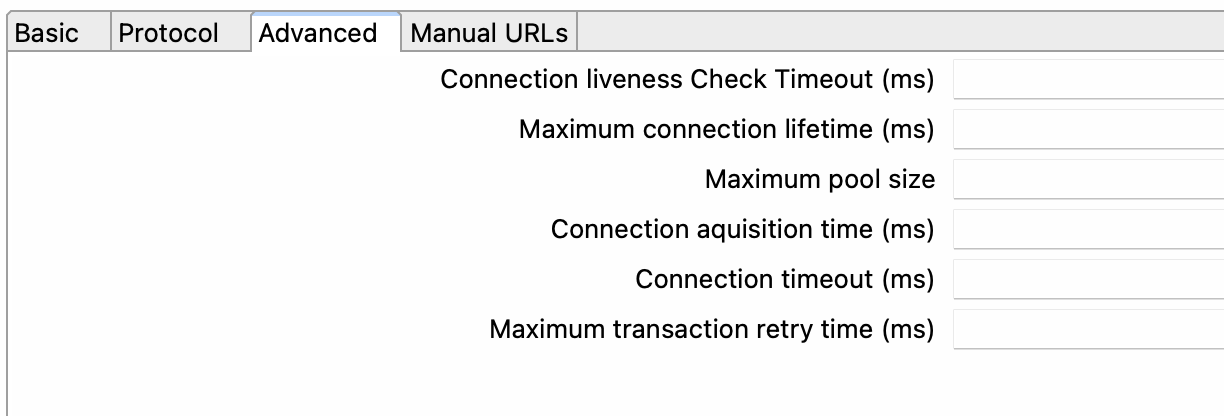
The Neo4j Connection metadata object in Apache Hop allows users to connect to a Neo4j graph database. This metadata object contains the necessary information to establish a connection, such as a host, port, username, and password. In addition, users can specify additional options such as encryption and trust strategy.
Basic tab
Advanced tab
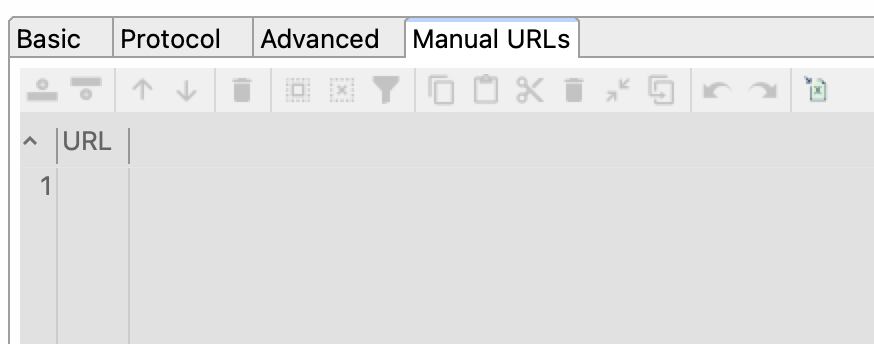
Manual URLs tab
Manual URLs: Specify a list of manual connection URLs to work with advanced features.
Once the Neo4j Connection metadata object is created, it can be used in Apache Hop transforms to read or write data to the connected Neo4j database.
The Neo4j Cypher transform, for example, allows users to specify the Neo4j Connection metadata object, as well as the query or statement to execute against the database.
It is also possible to use actions in workflows to check connections to Neo4j, run Neo4j scripts, and update constraints or indexes.
In future posts, we'll cover the entire list of Apache Hop plugins for Neo4j.
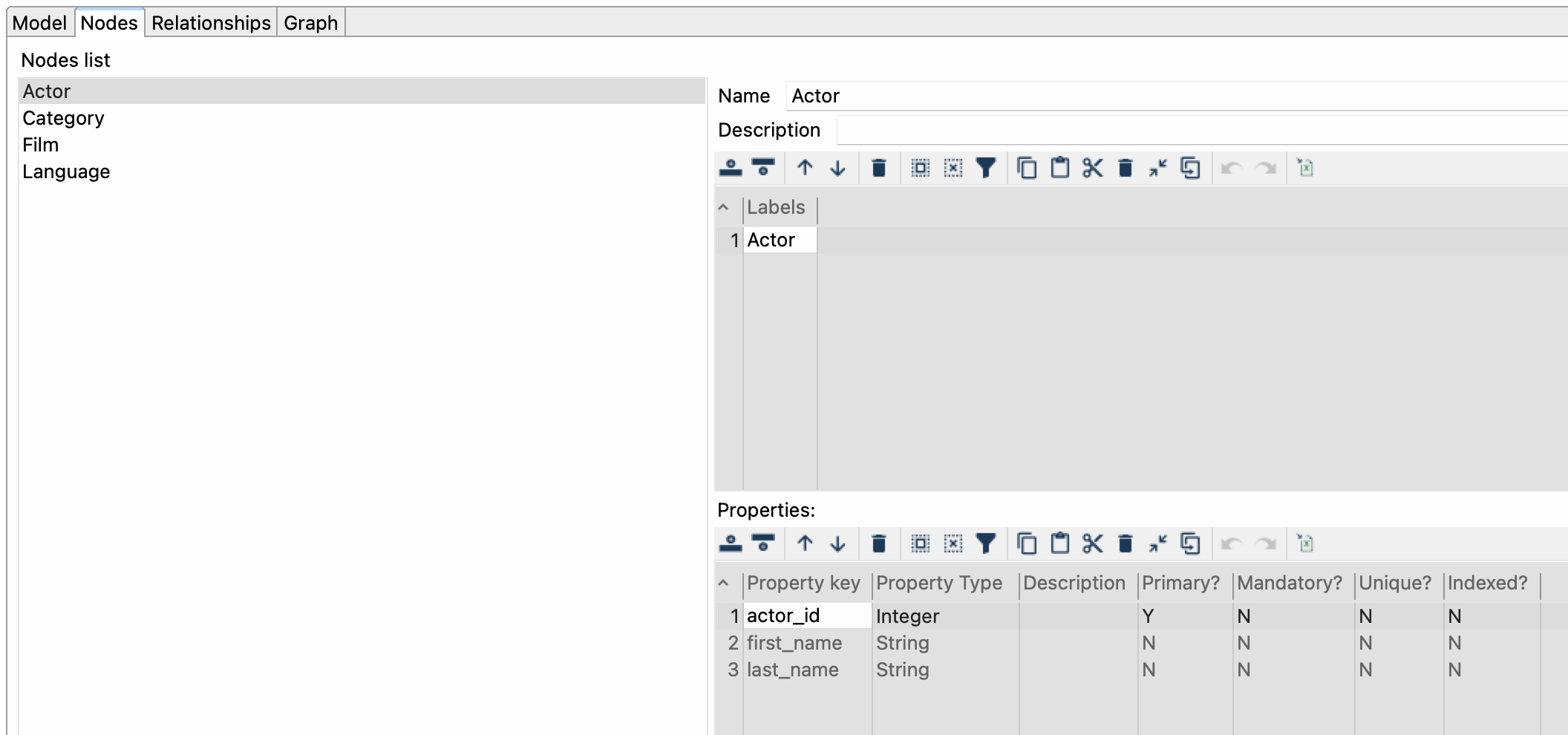
The Apache Hop metadata object for Neo4j Graph Model provides a way to define and manage metadata for a Neo4j graph database. The Neo4j Graph Model metadata object consists of two main components: nodes and relationships.
The nodes are defined by using labels that describe the nodes. Labels represent the nodes in the graph, and each label can have one or more properties associated with it.
The properties are defined as key-value pairs, where the key is the name of the property and the value is the data type of the property.
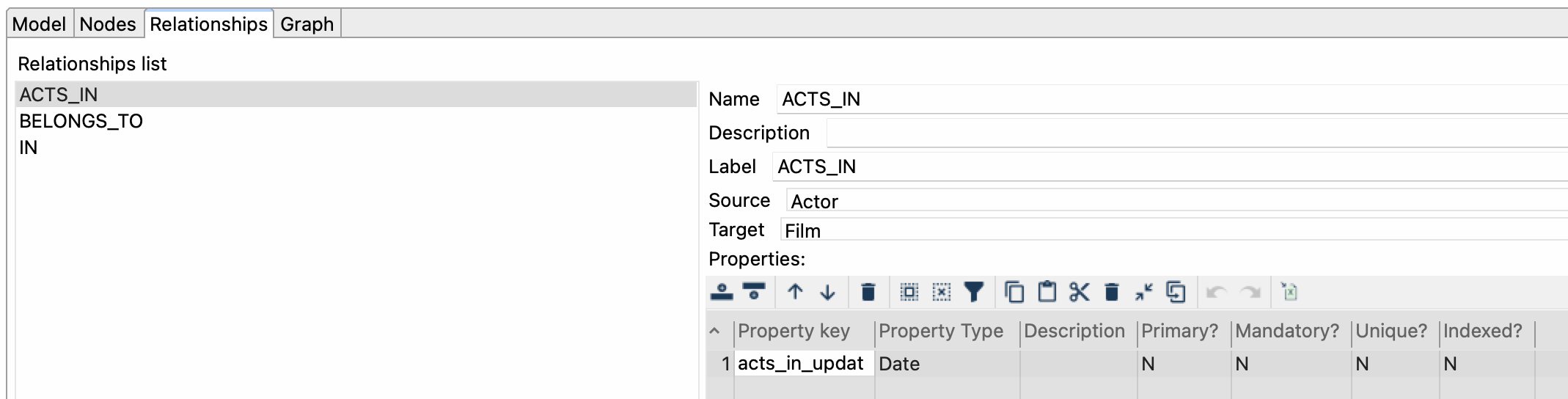
Relationships represent the edges between the nodes in the graph, and each relationship can have one or more properties associated with it. Like labels, the properties of relationships are defined as key-value pairs.
You can define a Neo4j Graph Model in Apache Hop as a metadata object. A graph model in Apache Hop allows you to create nodes with their attributes, as well as the connections or relationships between these nodes.
The following is an example of how a graph model is set up.
Model tab
Relationships tab
You can visually check the model you created.
This metadata object can then be used in transforms or actions within Apache Hop to interact with the Neo4j graph database. For example, the Graph Output transform in Apache Hop allows you to automatically map input fields to a graph model using a Neo4j Graph Model metadata object.
The MongoDB Connection metadata object in Apache Hop is used to define and configure a connection to a MongoDB database. Similar to the other database connections, this metadata object contains various settings for the connection, such as the hostname, port, username, password, and authentication database. Additionally, it allows the user to specify the database and collection that will be queried or written to in the MongoDB database.
Users can also define the read preference and write concern settings for the connection, which determine the behavior of the database in terms of data consistency and availability.
The main fields to be configured:
Once the MongoDB Connection metadata object is created, it can be used in Apache Hop transforms to read or write data to the connected MongoDB database. The MongoDB Input and MongoDB Output transforms allow users to specify the MongoDB Connection metadata object, as well as the query or field mapping to execute against the database. Users can also specify input and output field mappings to define how data is read from or written to the database.
It is also possible to use the MongoDB Delete transform to execute delete mappings against the database.
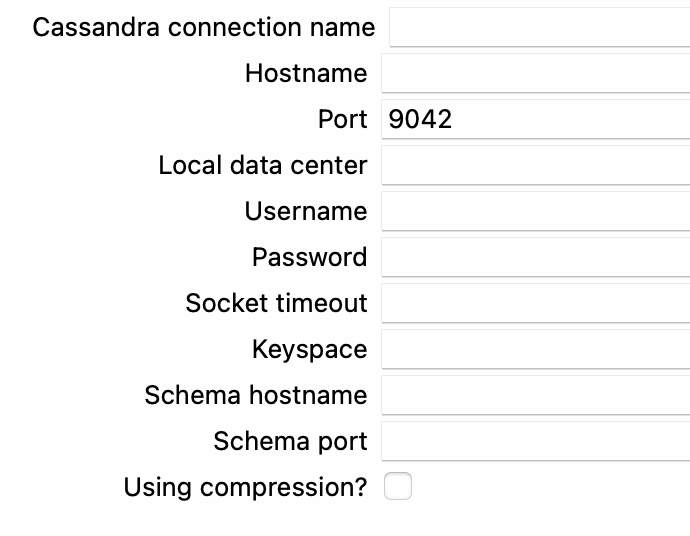
The Apache Hop metadata object Cassandra Connection allows users to connect to a Cassandra database to extract and load data. With this connection, users can define the host, port, keyspace, and other configuration options to establish a connection to a Cassandra database.
When defining a Cassandra connection, users should ensure that they have the necessary credentials and permissions to access the database. It's also important to choose appropriate options for consistency levels, compression, and other performance-related settings to ensure efficient data extraction and loading.
The metadata object Splunk Connection in Apache Hop is used to define the connection properties for accessing Splunk data. This metadata object allows users to set up a connection to a Splunk instance by specifying the host, port, and credentials required for authentication.
When creating a Splunk connection metadata object, users can specify the connection name, description, and connection properties. The connection properties include the host name, port number, scheme, and authentication credentials. Users can also choose to use a proxy server, and set a timeout value for the connection.
Once the Splunk connection metadata object is defined, users can use it in Apache Hop's pipeline and workflow designs to extract data from Splunk.
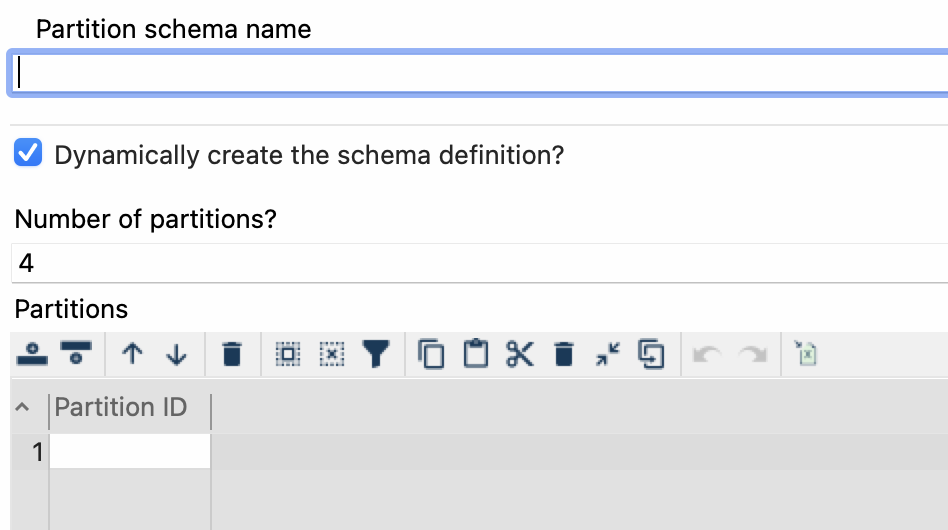
In Apache Hop, a metadata object partition schema represents the structure of a partitioned data set. This schema specifies the keys used for partitioning, the partition type, and any additional partitioning options. It is a crucial component in defining a data set that can be efficiently processed in parallel by distributed systems.
The partition schema in Apache Hop provides several partitioning options, including hash partitioning, range partitioning, and list partitioning. Hash partitioning distributes data evenly across partitions by hashing a key value, while ranging partitioning partition data based on a specified range of key values. List partitioning, on the other hand, partitions data based on a specific list of key values.
integration-tests/partitioning/0006-partitioned-when-stream-lookup-should-fail2.hpl
integration-tests/partitioning/0004-copies-repartitioning.hpl
integration-tests/partitioning/0001-static-partitioning.hpl
integration-tests/partitioning/0005-partitioned-stream-lookup.hpl
integration-tests/partitioning/0006-partitioned-when-stream-lookup-should-fail.hpl
integration-tests/partitioning/0003-repartitioning.hpl
integration-tests/partitioning/0005-non-partitioned-stream-lookup.hpl
integration-tests/partitioning/0002-dynamic-partitioning.hpl
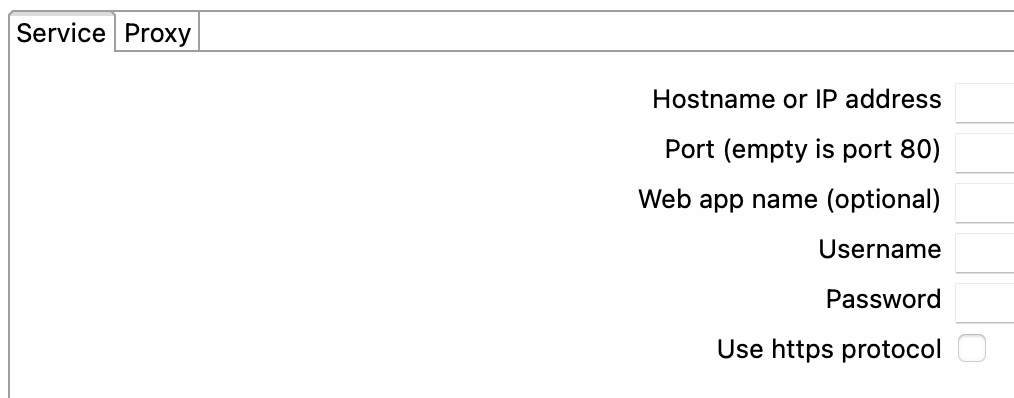
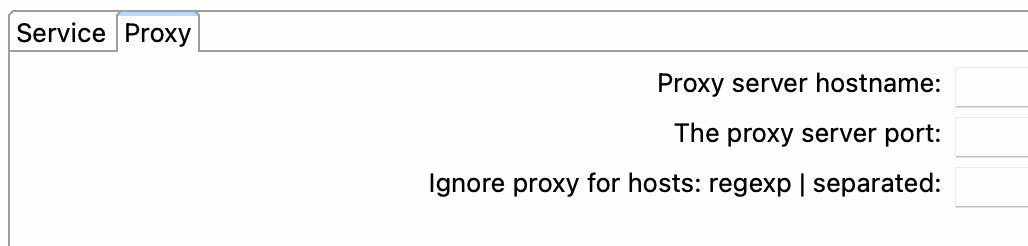
In Apache Hop, the Hop Server is a metadata object that allows you to remotely execute pipelines and workflows. It enables you to centralize the management and execution of your data integration processes in a single server that can be accessed by multiple users or applications. The Hop Server metadata object defines the properties required to connect to a Hop Server instance, such as the hostname, port number, username, and password.
Service tab
Proxy tab
Once the Hop server is defined, it can be used to facilitate the execution of workflows and pipelines remotely through the use of the Remote Pipeline or Remote Workflow run configurations. To run Hop Server, you can use the script available in your Hop installation directory. On Windows, the script is named "hop-server.bat", while on Mac and Linux, it is "hop-server.sh". If you run the script without any parameters, it will display the usage options for Hop Server. The Hop Server can be utilized in conjunction with the Web Service and Asynchronous Web Service metadata types. Check the Hop Official Documentation for more details.
Relationship between Hop Server and Pipeline and Workflow Run Configuration In Apache Hop, the Hop Server is the component that allows remote execution of pipelines and workflows. In the first post about this topic, we covered the Pipeline Run Configuration and the Workflow Run Configuration metadata objects. They allow users to specify and store runtime configuration settings for pipelines and workflows. One of the possible engine types is Hop remote engine. By specifying this engine the user can select a Hop Server metadata object to be used for the execution.
<metadata_folder>/path/to/your/metadata</metadata_folder>An example:
<hop-server-config> <hop-server> <name>8181</name> <hostname>localhost</hostname> <port>8181</port> </hop-server> <metadata_folder>/home/hop/project/services/metadata</metadata_folder> </hop-server-config>http://<hop-server-url>/hop/webServiceThis particular type of web service is designed for executing workflows that take a long time to complete. Unlike other web services that provide immediate results after a workflow is called, this service only returns a unique ID that represents the executing workflow. This ID can then be used to check the status of the workflow. Additionally, it is possible to specify additional variables that will be reported back when querying the status of the asynchronous workflow.
Relationship between Hop Server and Web Service
Using metadata objects in Apache Hop for data integration processes has several benefits:
Metadata objects simplify and standardize data processing across workflows and pipelines by providing a centralized way to manage common data integration elements such as database connections, file formats, and schema definitions. Rather than having to manually configure each of these elements for every workflow or pipeline, metadata objects can be defined once and reused across multiple processes.
This approach ensures consistency across data integration processes, reducing the risk of errors and improving data quality. Additionally, metadata objects can be easily updated and maintained, making it simpler to manage changes to data sources, targets, or processing logic.
By providing a standard way to define and manage metadata objects, Apache Hop streamlines the development and deployment of data integration processes. This approach makes it easier for teams to collaborate on data integration projects and ensures that processing is consistent, repeatable, and reliable across different environments and use cases.
Here are some best practices for using metadata objects in Apache Hop:
Following these best practices, you can use metadata objects in Apache Hop to streamline your data integration processes, making them more efficient and easier to manage over time.
This post provides an overview of metadata objects in Apache Hop, an open-source data integration tool. The post explains the importance of metadata objects and their different types, including 10 of the 20 metadata types in Apache Hop. The benefits of using metadata objects include reusability, consistency, manageability, and flexibility. The post also provides best practices for creating and managing metadata objects in Apache Hop.
In Apache Hop, metadata objects are used to define the inputs and outputs of pipelines, the format and structure of data sources and targets, and the configuration of various Hop components. They are stored in a centralized metadata repository, which allows for easy access and management of metadata objects across multiple projects.
Metadata objects also enable the automation of data integration processes by providing a way to programmatically manipulate and configure pipelines and workflows. By defining metadata objects once, they can be reused across multiple pipelines and workflows, saving time and effort in development and maintenance.
{kind=link}